Este documento describe la capa de acceso a datos de gvSIG (denominada Data Access Library, DAL para abreviar) tras la reingeniería realizada en la rama v2_0_0_prep.
Con DAL se pretende dotar a gvSIG de una capa de abstracción que permita al núcleo de la aplicación operar de forma homogénea con diferentes fuentes y formatos de datos. Su arquitectura se basa en la flexibilidad y la robustez, y por ello aspectos como el desacoplamiento y la trazabilidad son esenciales en su diseño. Algunas características de DAL:
- Es extensible a través de un marco común.
- Reduce el acoplamiento entre las distintas capas de la aplicación y los proveedores de datos.
- Mejora la trazabilidad en el acceso a datos.
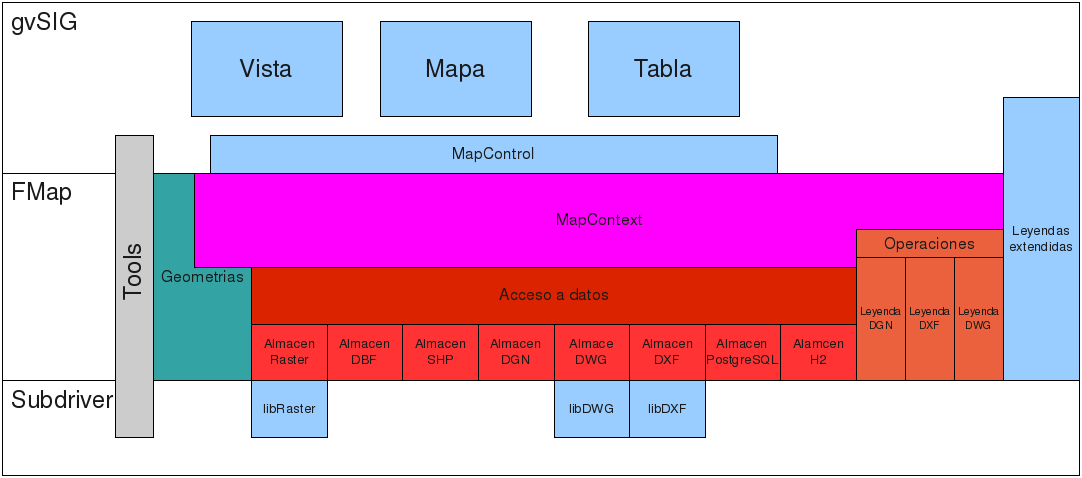
En el siguiente diagrama podemos ver donde encajan los distintos componentes
de la librería de acceso a datos en gvSIG.
Los componentes que formarían parte de la librería de acceso a datos serían:
- La librería de acceso a datos
- Los distintos almacenes de datos
- Las operaciones, manejo de leyendas específicos de algunos formatos.
Íntimamente relacionados con estos estaría la librería de geometrías, y las librerías
de manejo de DWG y DXF.
El acceso a datos de gvSIG contiene dos grandes conjuntos de interfaces:
- El primero para los consumidores de datos o API.
- Y el segundo, para los proveedores de datos de la librería o SPI.
La descripción de cada uno de esos grupos de interfaces se realizará por separado, distinguiendo en todo momento entre los servicios que se ofrecen al consumidor de datos y al proveedor de éstos.
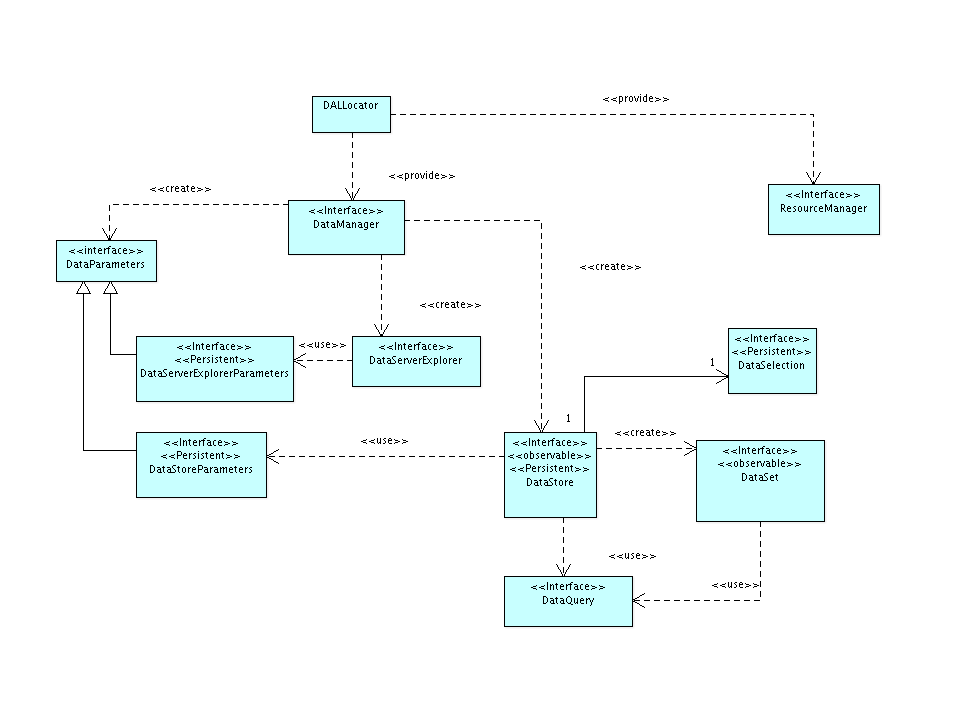
En la arquitectura de la librería de acceso a datos, DAL, existen tres piezas fundamentales que se encuentran interrelacionadas entre sí:
- Control de recursos, Resource. Identifica qué recursos están siendo
usados en todo momento por los distintos proveedores de datos de la
librería, pudiendo solicitar que se liberen en un momento dado.
- Acceso a los servicios de un servidor de datos, DataServerExplorer.
Permite determinar qué almacenes de datos hay en un servidor, así como
crear nuevos almacenes. Los principales tipos de servidores soportados
son:
- Sistemas de ficheros en local, FilesystemServerExplorer.
- Sistemas de bases de datos con soporte JDBC, JDBCServerExplorer.
- Sistemas remotos basados en WMS/WCS.
- Sistemas remotos basados en WFS/WFS-T, WFSServerExplorer.
- Acceso a los datos de un almacen, DataStore. Nos permite el acceso a
datos de tipos como:
- dbf/shp
- dxf
- GML
- Bases de datos PostgreSQL
El API provee de una primera capa de abstracción que representa al acceso a datos independientemente de si estamos accediendo a datos tabulares, vectoriales o coberturas raster, para luego disponer de especializaciones dependiendo de si estamos accediendo a datos vectoriales o coberturas raster.
En la primera aproximación a la librería nos encontramos una serie de clases e interfaces que son independientes del tipo de datos y de su origen. Estas son:
- DALLocator. Se trata del locator de la librería. Nos proporciona los servicios de localización del DataManager y el ResourceManager a usar por la librería.
- DataManager. Se trata de la factoría que nos da acceso al API de acceso a
datos. A partir de él podemos acceder a los almacenes de datos o explorar
los almacenes de datos que nos suministra un servidor o servicio dado. Es
el punto de entrada a todo el modelo de objetos.
- DataStore. Representa un almacén de datos. Un fichero shape o una tabla de
una base de datos, y dispone de mecanismos para acceder a sus datos, su estructura
y tipo, así como en qué forma se pueden modificar éstos.
- DataStoreParameters. Representa el conjunto de parámetros que se necesitan
para poder acceder al almacén de datos. Por ejemplo, si estamos accediendo
a un fichero dbf, contendrá la ruta al fichero.
- DataSet. Representa un conjunto de datos del almacén de datos.
El DataStore contiene mecanismos para acceder a los datos, permitiendo
aplicar filtros u órdenes a éstos, así como información contextual que
pueda ser útil a la hora de decidir cómo ha de realizarse de forma óptima
la recuperación de éstos desde el almacén.
- DataQuery. Representa el conjunto de valores que conforman las condiciones
en las que se basará el DataSet para recuperar y devolver los datos.
- DataServerExplorer. Nos permite obtener la lista de almacenes disponibles en un
servidor o servicio dado. Así podemos pedirle que nos dé la lista de tablas
de una base de datos o de ficheros susceptibles de ser tratados como almacenes,
por ejemplo shapes, dbfs o dxfs, que existan en una capeta dada. A partir
de la información que nos suministre sobre cada almacén, podremos crear
el DataStore adecuado para acceder a sus datos.
- DataExplorerParameters. Representa el juego de parámetros necesario para
poder acceder al servidor o servicio y poder consular los almacenes de datos
que éste sirve.
Así, puede pasarle un DataStoreParameters al DataManager para obtener un DataStore, y a partir de éste realizar consultas contra ese almacén o modificar sus datos. Una consulta devolverá un DataSet y a partir de él podrá acceder a los datos. Si queremos saber qué almacenes de datos tenemos en un servidor podemos pedirle un DataServerExplorer al DataManager y éste nos informará de los almacenes de datos que hay disponibles.
A partir de esta primera capa de abstracción que provee la librería, aparecen dos
grandes especializaciones de ella:
- Por un lado aparece una especialización que nos da acceso a datos de tipo
tabular, bien sean de tipo alfanumérico o vectorial.
- Por otro, una especialización que nos abre el acceso a datos de tipo
coberturas raster.
En adelante describiremos cada una de estas especializaciones, primero
centrándonos en el acceso a datos tabulares y después a los raster.
También trataremos más adelante cómo llevar la gestión de los recursos usados por
la librería, ficheros, conexiones a BBDD, conexiones a servicios remotos, ...
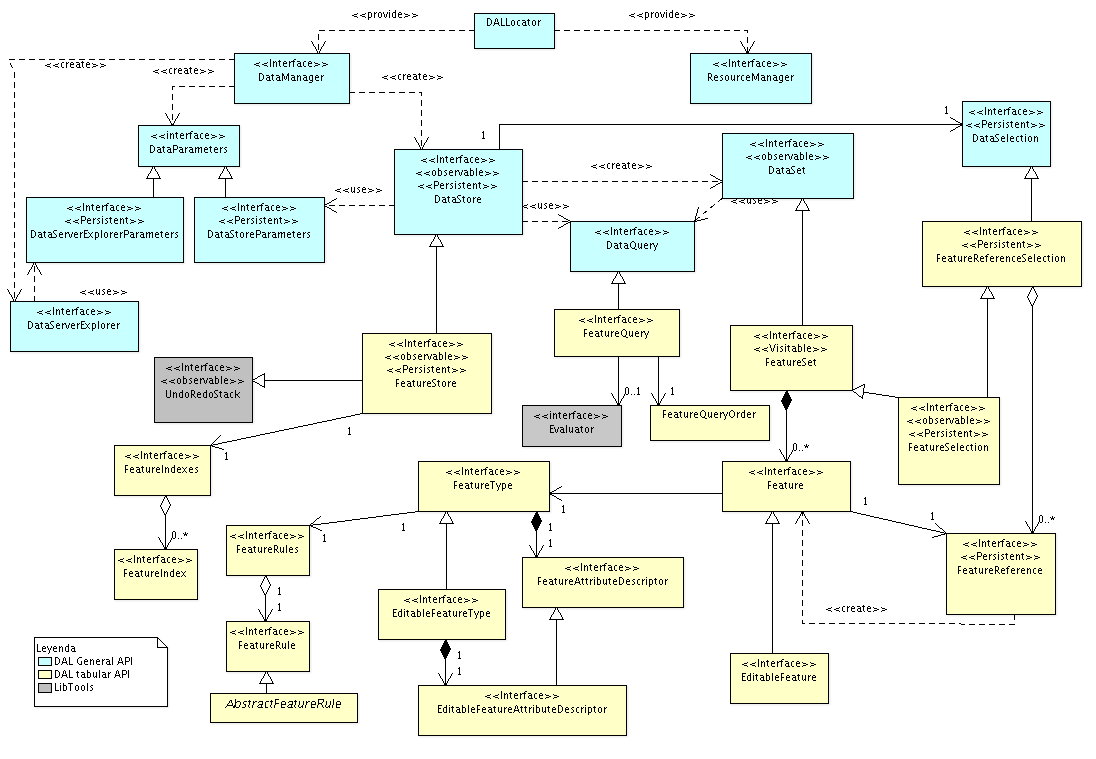
Partiendo de la arquitectura general del API de acceso a datos, podemos
ver como encaja la especialización del acceso a datos tabulares dentro de ella.
Dentro del acceso a datos tabulares se incluye tanto el acceso a datos de
carácter alfanumérico como vectorial, soportando que uno o varios atributos
de un ítem o fenómeno sean de tipo vectorial.
Nos encontraremos las siguientes clases e interfaces mostradas en el siguiente
gráfico.
- FeatureStore, como especialización de DataStore.
Añade funcionalidades propias del acceso a datos alfanuméricos
y vectoriales. Conoce de fenómenos, cómo consultar sus valores
o su estructura, así como de acciones específicas para acceder
a ellos.
- FeatureSet, como especialización de DataSet.
Conoce los fenómenos y es capaz de iterar sobre ellos.
- FeatureQuery, como especialización de DataQuery. Contiene
información relevante sobre la definición de filtros y su ordenación
que hace uso del conocimiento de estar trabajando sobre datos alfanuméricos
y vectoriales.
- Feature. Aparece como contenedor de un fenómeno, permitiendo acceder
a la información de éste.
- FeatureType. Aparece como el contenedor de la estructura de un fenómeno.
Qué atributos tiene o de qué tipo son.
Así por ejemplo, si quisiésemos acceder a los fenómenos de un fichero shape, podríamos hacerlo con:
DataManager manager;
DataStoreParameters params;
FeatureStore store;
FeatureSet features;
Feature feature;
manager = DALLocator.getDataManager();
params = manager.createStoreParameters("Shape");
params.setDynValue("shpfilename","data/prueba.shp");
store = (FeatureStore)manager.createStore(params);
features = store.getFeatureSet();
DisposableIterator it = features.iterator();
while( it.hasNext() ) {
feature = (Feature)it.next();
System.out.println(feature.getString("NOMBRE"));
}
it.dispose();
features.dispose();
store.dispose();
Y por ejemplo, si en lugar de un fichero en disco fuese una tabla de
una BBDD postgres sería algo como:
DataManager manager;
DataStoreParameters params;
FeatureStore store;
FeatureSet features;
Feature feature;
manager = DALLocator.getDataManager();
params = manager.createStoreParameters("PostgreSQL");
params.setDynValue("host", SERVER_IP);
params.setDynValue("port", SERVER_PORT);
params.setDynValue("dbuser",SERVER_USER);
params.setDynValue("password",SERVER_PASWD);
params.setDynValue("schema",SERVER_SCHEMA);
params.setDynValue("dbname",SERVER_DBNAME);
params.setDynValue("table","prueba");
store = (FeatureStore)manager.createStore(params);
features = store.getFeatureSet();
DisposableIterator it = features.iterator();
while( it.hasNext() ) {
feature = (Feature)it.next();
System.out.println(feature.getString("nombre"));
}
it.dispose();
features.dispose();
store.dispose();
Otra alternativa mas recomendable para no tener que preocuparnos
por liberar los recursos del FeatureSet y el iterador seria
usando un visitor sobre el FeatureStore:
DataManager manager;
DataStoreParameters params;
FeatureStore store;
manager = DALLocator.getDataManager();
params = manager.createStoreParameters("Shape");
params.setDynValue("shpfilename","data/prueba.shp");
store = (FeatureStore)manager.createStore(params);
store.accept( new Visitor() {
public void visit(Object obj) {
Feature feature = (Feature)obj;
System.out.println(feature.getString("NOMBRE"));
}
}
);
store.dispose();
Acceso básico
Dentro de este apartado veremos:
- Como recorrer los fenómenos de un shape.
- Como manejarse con un conjunto de fenómenos.
- Acciones asociadas a un Feature para consultar
los valores de sus atributos.
Veamos ahora a seguir este documento con un ejemplo simple. Accederemos a un fichero shape y recorreremos todos sus fenómenos.
Lo primero que tendremos que hacer será conseguir una instancia del DataManager
del API de acceso a datos. Esto se consigue mediante la llamada al método
estático, getDataManager de la clase DALLocator.
manager = DALLocator.getDataManager();
Una vez conseguido la instancia del DataManager , utilizaremos este para conseguir
una instancia de los parámetros que necesitamos para acceder al almacén de
nuestro fichero shape. Para eso invocaremos al método createStoreParameters
indicándole el tipo de almacén al que queremos acceder.
params = manager.createStoreParameters("Shape");
En el caso de un almacén de tipo shape, el único parámetro que necesitaremos
será el nombre del fichero al que queremos acceder. Los parámetros se comportan
como un Map, así que asignaremos a la clave shpfilename, el nombre del fichero al
que queremos acceder.
params.setDynValue("shpfilename","data/prueba.shp");
Una vez tenemos los parámetros del almacén al que queremos acceder preparados,
le indicaremos al manager que nos cree un DataStore acorde a esos parámetros que
nos permita acceder a nuestro fichero. Esto se hará llamando al método createStore
pasándole como argumento los parámetros que ya hemos preparado. Esta llamada nos
devolverá un FeatureStore , y ya con el podremos acceder a sus fenómenos.
store = (FeatureStore)manager.createStore(params);
Cuando ya disponemos del store, podemos utilizar este para acceder a sus fenómenos.
La forma mas simple de hacer esto seria visitar el almacen.
store.accept( new Visitor() {
public void visit(Object obj) {
Feature feature = (Feature)obj;
...
}
}
);
Como alternativa a este metodo podemos usar el método getFeatureSet,
que nos devolverá un conjunto de fenómenos, FeatureSet , con el que podremos
operar.
features = store.getFeatureSet();
Es importante entender que estas son las unicas formas de acceder a los
fenómenos de un almacén. Además estas nos
permiten dado un almacén de datos acceder de forma simultanea a sus fenómenos invocando desde
varias partes de la aplicación al método accept o getFeatureSet para obtener distintos conjuntos de datos.
Como norma general no deberemos usar un conjunto de fenómenos, FeatureSet .
desde varias partes de la aplicación simultáneamente. Si necesitamos acceder a los
datos del almacén, allá donde se necesite, se creará un nuevo conjunto de datos.
Los principales métodos de un FeatureSet son:
- getDefaultFeatureType
- getFeatureTypes
- isEmpty
- getSize
- dispose
- iterator
- fastiterator
Hacer una mención especial sobre los dos últimos métodos, iterator y
fastiterator. El primero, iterator, devuelve una nueva instancia de Feature
cada vez que se invoca al método next. El segundo, fastiterator devuelve
siempre la misma instancia de Feature al invocar al método next, alterando
el valor de esta de forma que está cargada con los valores del nuevo fenómeno.
Este comportamiento nos ahorra crear tantos objetos Feature como elementos
tenga el conjunto, pero deberemos tener especial cuidado en no guardarnos
una referencia a los objetos Feature así obtenidos ya que irán alterando su valor
conforme se itere sobre el conjunto.
El FeatureSet, ademas de los metodos para iterar sobre el tambien nos permite
visitarlo, siendo siempre recomendable utilizar este mecanismo frente al recorrido
mediante un iterador.
Volviendo al ejemplo sobre el que estábamos trabajando,
podemos obtener un iterador sobre el conjunto de todas los fenómenos
y recorrerlos. En el ejemplo accederemos al valor del atributo NOMBRE
del fenómeno y lo sacaremos por la salida estándar.
DisposableIterator it = features.iterator();
while( it.hasNext() ) {
feature = (Feature)it.next();
System.out.println(feature.getString("NOMBRE"));
}
it.dispose();
Tenemos también la opción de saltar directamente a una posición, pidiendo el DisposableIterator
con un índice. Podemos usar el DisposableIterator devuelto de la misma forma que con
el DisposableIterator normal, aunque el primer elemento devuelto será el que ocupa la posición
correspondiente al índice indicado:
DisposableIterator it = features.iterator(100);
while( it.hasNext() ) {
feature = (Feature)it.next();
System.out.println(feature.getString("NOMBRE"));
}
it.dispose();
Por último una vez hemos terminado de trabajar con el conjunto de fenómenos y el almacén
debemos informarles de ello, para que este libere todos los recursos que esté utilizando.
features.dispose();
store.dispose();
Es importante tener en cuenta algunas consideraciones.
Los elementos de un FeatureSet son siempre del tipo Feature , pero si no
hemos indicado nada al respecto cuando creamos el conjunto, no deberemos asumir
que todos tienen la misma estructura, ya que dependiendo del tipo de almacén podemos
encontrarnos con que la estructura de estos puede cambiar de un elemento a otro. Más adelante
explicaremos como filtrar los conjuntos de fenómenos de forma que el tipo de elementos
sea único dentro de este.
Otro punto a tener en cuenta está relacionado con la implementación del recorrido
de los elementos de un conjunto. No deberemos asumir nada al respecto de esto. El
API no fija nada respecto a como debe implementar cada almacén el recorrido de sus
elementos. Puede haber almacenes que carguen todos sus elementos en memoria para ser recorridos
mientras que otros sólo mantengan en memoria el elemento que se va a devolver o incluso
otros que utilicen algoritmos de cache específicos para acelerar su acceso. En general
la implementación de los distintos almacenes que lleva de base esta librería tiende a
ser lo mas óptima posible, balanceando la carga en memoria y la velocidad de acceso, e
implementándose de una u otra forma en función de las características del almacén.
Por último es importante invocar a la acción dispose del conjunto de fenómenos cuando
dejemos de trabajar con él, así como de los DisposableIterator cuando dejemos de usarlos.
Dependiendo del tipo de almacén, esto puedo liberar recursos como ficheros abiertos en disco
o conexiones a BBDD. Así mismo cuando hayamos creado nosotros el almacén, debemos de
encargarnos de invocar a la acción dispose sobre este. Hay que
tener cuidado de no invocar a la acción dispose sobre un almacén asociado a una capa de
gvSIG. Será la propia capa de gvSIG la encargada de hacerlo cuando no lo necesite.
Veamos todo el código del ejemplo junto:
DataManager manager;
DataStoreParameters params;
FeatureStore store;
FeatureSet features;
Feature feature;
manager = DALLocator.getDataManager();
params = manager.createStoreParameters("Shape")
params.setDynValue("shpfilename","data/prueba.shp");
store = (FeatureStore)manager.createStore(params);
features = store.getFeatureSet();
DisposableIterator it = features.iterator();
while( it.hasNext() ) {
feature = (Feature)it.next();
System.out.println(feature.getString("NOMBRE"));
}
it.dispose();
features.dispose();
store.dispose();
Aunque siempre se pueden utilizar iteradores para recorrer los elementos del
almacen, es recomendable cuando sea posible utilizar visitors. Estos nos
garantizan que se libreran los recursos de forma automatica sin tener que
ir invocando a los metos dispose del iterador o el conjunto de fenomenos.
El codigo usando visitors quedaria algo como:
DataManager manager;
DataStoreParameters params;
FeatureStore store;
FeatureSet features;
Feature feature;
manager = DALLocator.getDataManager();
params = manager.createStoreParameters("Shape")
params.setDynValue("shpfilename","data/prueba.shp");
store = (FeatureStore)manager.createStore(params);
store.accept( new Visitor() {
public void visit(Object obj) {
Feature feature = (Feature)obj;
System.out.println(feature.getString("NOMBRE"));
}
}
);
store.dispose();
Hasta aquí hemos visto como conseguir usar el API para llegar a obtener un objeto
Feature . Pero, ¿ qué es un Feature y qué servicios nos ofrece ?
La clase Feature representa a un fenómeno dentro del almacén. En él se aglutina
toda la información, ya sea alfanumérica o vectorial. Un Feature se comporta
como un Map muy especializado en el que las key hacen referencia a los nombres
de los atributos del fenómeno y los value de estas al valor de estos atributos. Cada
atributo tiene su tipo, por lo que no hay limitación en cuanto a cuantos atributos
de tipo vectorial puede tener la definición de una Feature .
En Feature nos encontraremos un método get para acceder a los valores de los atributos
del fenómeno. Para facilitar el acceso se han añadido métodos de utilidad que nos
devuelven ya tipos concretos en lugar de Object. Así, en el ejemplo anterior,
se usa el getString para obtener el valor del atributo NOMBRE como un String.
Los métodos de acceso a los valores de los atributos de un Feature son:
- get, retorna el valor del atributo indicado como
un Object.
- getInt, retorna el valor del atributo como
un valor de tipo int.
- getBoolean, retorna el valor del atributo como
un valor de tipo boolean.
- getLong, retorna el valor del atributo como
un valor de tipo long.
- getFloat, retorna el valor del atributo como
un valor de tipo float.
- getDouble, retorna el valor del atributo como
un valor de tipo double.
- getDate, retorna el valor del atributo como
un valor de tipo Date.
- getString, retorna el valor del atributo como
un valor de tipo String.
- getByte, retorna el valor del atributo como
un valor de tipo byte.
- getGeometry, retorna el valor del atributo como
un valor de tipo Geometry.
- getFeature, retorna el valor del atributo como
un valor de tipo Feature .
- getArray, retorna el valor del atributo como
un valor de tipo Object[].
Para los tipos básicos, si el valor del
atributo pedido no es del tipo pedido se intentará
convertir a ese tipo y en caso de que no se pueda
se lanzará una excepción.
Conviene comentar sobre los últimos tres métodos.
En lo que se refiere al acceso a datos, los valores
de datos de tipo vectorial los trata como objetos de tipo
Geometry . Este tipo de datos esta definido en la librería
de geometrías de gvSIG, org.gvsig.fmap.geom para más información
sobre las funcionalidades alrededor de este tipo consulte la
documentación de esta librería (ver en documentos relacionados).
En lo que respecta al método getFeature, está pensado para
dar soporte a fuentes de datos en las que un fenómeno dentro de
la fuente de datos tiene un atributo que a su vez es una estructura
compleja, con sus propios atributos y valores. La forma de
recuperar ese atributo compuesto, por referirnos a él de alguna
forma, será a través de este método.
En lo que respecta al método getArray viene a cubrir el hueco de
qué pasa cuando un atributo de un fenómeno está compuesto por una tupla
de valores. Para acceder a esta tupla de valores se usará este método
que nos la presentará como un array.
Ahora unas consideraciones sobre rendimientos.
En general es recomendable usar el nombre del atributo para acceder
a el valor de estos, ya que, para cada consulta podemos variar tanto en
orden como en cantidad los atributos de la Feature que deseamos. Sin embargo
en ocasiones puede resultar mas óptimo usar su índice para acceder
a él. Todos los métodos de acceso que acabamos de comentar están sobrecargados
de forma que podemos usar bien el nombre o bien su índice.
Veamos como podía usarse esta forma de acceso a los atributos en el
ejemplo anterior.
DisposableIterator it = features.iterator();
while( it.hasNext() ) {
feature = (Feature)it.next();
featureType = feature.getType();
index = featureType.getIndex("NOMBRE");
System.out.println(feature.getString(index));
}
it.dispose();
Evidentemente, el cambio, así introducido no ha supuesto ninguna mejora
en el rendimiento. Ahora bien si asumimos que estamos trabajando con
un almacén de datos que sólo soporta un tipo de Feature , como es
nuestro caso, podemos optimizar algo mas el acceso.
featureType = store.getDefaultFeatureType();
index = featureType.getIndex("NOMBRE");
DisposableIterator it = features.iterator();
while( it.hasNext() ) {
feature = (Feature)it.next();
System.out.println(feature.getString(index));
}
it.dispose();
Esto sí que puede resultar en una ganancia considerable en rendimientos
cuando estemos accediendo a un almacén con un numero muy grande de
fenómenos.
Cabe resaltar que hemos utilizado en el ejemplo un par de métodos nuevos.
Por un lado podemos ver como dada un Feature accedemos a su tipo mediante
el método getType, que nos devuelve un objeto del tipo FeatureType .
Y por otro lado, podemos obtener el tipo de los fenómenos de un almacén
mediante el método getDefaultFeatureType . Hay que tener cuidado con el
uso de este método ya que cuando estemos trabajando con almacenes que
contengan Feature de varios tipos, nos dará de forma arbitraria sólo
un tipo. Si queremos saber los tipos de fenómenos que contiene un
almacén deberemos invocar a getFeatureTypes que nos devolverá una
lista de los FeatureType que tiene el almacén.
Puede ser conveniente repasar la referencia sobre:
Filtrado
Dentro de este apartado veremos:
- Como obtener un conjunto de fenómenos filtrando
por tipo de fenómeno.
- Como obtener un conjunto de fenómenos filtrando
por una condición en función de los atributos
de los fenómenos.
Vamos a seguir trabajando sobre el ejemplo que hemos estado viendo en el
apartado anterior. ¿ Como podemos obtener un subconjunto de fenómenos de
nuestro almacén ?
Para aplicar un filtro, este se aplicara en el momento de invocar al
método getFeatureSet de nuestro almacén. Para esto deberemos
construir un objeto FeatureQuery , rellenarlo con los valores con los
que queremos filtrar e invocar al getFeatureSet pasándole
ese query.
A la hora de filtrar los fenómenos de un almacén de datos, podemos hacerlo
llevándonos de dos tipos de criterios:
- Según el tipo de fenómeno
- O según una condición de filtro en función de los valores
de los fenómenos del almacén.
Por ejemplo podríamos asegurarnos que cuando nos recorremos los fenómenos
siempre nos da fenómenos del mismo tipo, para ello podríamos hacer:
types = store.getFeatureTypes();
Iterator typesIterator = types.iterator();
while( typesIterator.hasNext() ) {
featureType = (FeatureType)typesIterator.next();
index = featureType.getFieldIndex("NOMBRE");
FeatureQuery query = store.createFeatureQuery();
query.setFeatureType(featureType);
features = store.getFeatureSet(query);
DisposableIterator featuresIterator = features.iterator();
while( featuresIterator.hasNext() ) {
feature = (Feature)featuresIterator.next();
System.out.println(feature.getString(index));
}
featuresIterator.dispose();
features.dispose();
}
Primero averiguamos los tipos de fenómenos que contiene nuestro almacén,
y luego obtenemos los fenómenos filtrando por tipo. Para filtrar creamos
un FeatureQuery a partir del store.
FeatureQuery query = store.createFeatureQuery();
Indicamos que queremos filtrar por los fenómenos de un tipo
en concreto.
query.setFeatureType(featureType):
y por ultimo creamos el conjunto de fenómenos usando ese
filtro.
features = store.getFeatureSet(query);
Al igual que podiamos emplear visitor sobre un almacen para
acceder a sus fenomenos, cuando estamos aplicando un filtro
tambien podemos usar el concepto de visitor, ya que el
almacen dispone de un metodo acept que recibe un query.
store.accept( new Visitor() {
public void visit(Object obj) {
..
}
},
query
);
De forma similar a como filtramos por el tipo de fenómeno podemos
filtrar por una expresión en función de los atributos de los
fenómenos. Para ello deberemos crear un objeto Evaluator con la
condición que deseemos. Así el código de filtrado podría ser:
FeatureQuery query = store.createFeatureQuery();
query.setFilter( manager.createExpresion("NOMBRE like 'a%'") );
features = store.getFeatureSet(query);
...
features.dispose();
Hay que tener en cuenta que podemos mezclar los dos tipos de filtro,
filtrando a su vez por los tipo de fenómeno y por una expresión.
FeatureQuery query = store.createFeatureQuery();
query.setFilter( manager.createExpresion("NOMBRE like 'a%'") );
query.setFeatureType(featureType):
features = store.getFeatureSet(query);
...
features.dispose();
A la hora de aplicar un filtro a un query, debemos entregarle un objeto
de tipo Evaluator . El DataManager dispone de un evaluador por defecto
para la evaluación de expresiones, pero se pueden utilizar evaluadores
especializados para obtener mejores rendimientos.
Puede ser conveniente repasar la referencia sobre:
Ordenación
La ordenación de los fenómenos devueltos por getFeatureSet se realiza
de forma similar a como se aplican los filtros. El orden que queremos aplicar
a nuestra colección de fenómenos se indica al FeatureQuery a través del
método getOrder, que nos devuelve una objeto FeatureQueryOrder .
Así para ordenar los registros de forma ascendente por el atributo "NOMBRE"
haríamos:
FeatureQuery query = store.createFeatureQuery();
query.getOrder().add("NOMBRE",true);
query.setFilter( manager.createExpresion("NOMBRE like 'a%'") );
features = store.getFeatureSet(query);
...
features.dispose();
Nótese que se pueden especificar simultáneamente tanto condiciones de filtrado por
expresión, por tipo de fenómeno y a su vez con o sin una ordenación.
Si quisiésemos hacer una ordenación descendente en lugar de usar:
order.add("NOMBRE",true);
Usaríamos
order.add("NOMBRE",false);
También es posible usar un Evaluator para la ordenación. Por ejemplo,
podemos hacer que la ordenación no distinga mayúsculas de las minúsculas así:
query.getOrder().add(manager.createExpresion("lower(NOMBRE)"),true);
Contexto
En ocasiones nos encontramos que dependiendo de algunas condiciones ajenas
a los datos en si mismos, no seria necesario disponer de un conjunto completo
de los fenómenos de un almacén, y si el almacén conociese cierta
información podría realizar optimizaciones en como recoge o recorre los
fenómenos que contiene para devolverlos a la aplicación. Esta información
adicional que no forma parte de los filtros u ordenaciones es lo que
denominamos contexto.
Nótese que cuando se indica una información de contexto para que el almacén
haga uso de ella y optimizar el acceso a los datos, la información que
nos devuelve la consulta no sera rigurosa. Por ejemplo, cuando estamos accediendo
a un servicio remoto de recuperación de fenómenos para pintarlos, si suministramos
a la consulta información de la escala, este puede obviar traerse del servidor
los fenómenos que no sean representativos de la escala a la que se este
trabajando e incluso simplificar las geometrías para optimizarlas en
función de la escala a la que van a ser usadas. Esto constituiría una optimización
durante el pintado de los datos, pero la información descargada nadie nos asegura
que fuese rigurosa. Así cuando vallamos a usar los datos para aplicar geoprocesos
o estemos interesados en realizar edición sobre ellos, nunca deberíamos indicar
en la consulta información de contexto.
Actualmente la única información de contexto prefijada que se trata en la
librería de acceso a datos es la escala. Se puede indicar información de contexto
adicional a modo de pares clave-valor. Hay que tener en cuenta que aunque se
especifique información de contexto, si el almacén no sabe como tratar
esa información de contexto, esta no se usará.
Imaginemos que estamos trabajando con capas de puntos obtenidas a partir de
un vuelo LIDAR. La cantidad de fenómenos asociado a esa fuente de datos puede
ser altísima, así que a la hora de pintar esos fenómenos nos gustaría que
tratase de hacer todas las optimizaciones que pudiese y, muy probablemente,
el uso de la información de escala a la cual voy a usar esos datos permita
acelerar mucho su acceso. Así podríamos indicar esa información al
obtener la colección de fenómenos.
FeatureQuery query = store.createFeatureQuery();
query.setScale(scale);
features = store.getFeatureSet(query);
...
features.dispose();
Esta información de contexto podría acumularse a las otras informaciones de
ordenación o filtrado de una consulta.
FeatureQuery query = store.createFeatureQuery();
query.getOrder().add("NOMBRE",true);
query.setFilter( manager.createExpresion("NOMBRE like 'a%'") );
query.setScale(scale);
features = store.getFeatureSet(query);
...
features.dispose();
Otra forma alternativa de indicar la escala como información de contexto seria:
FeatureQuery query = store.createFeatureQuery();
query.getOrder().add("NOMBRE",true);
query.setFilter( manager.createExpresion("NOMBRE like 'a%'") );
query.setQueryParameter("Scale",scale);
features = store.getFeatureSet(query);
...
features.dispose();
De esta forma podrían indicarse otros valores de contexto que el
almacén de datos pueda utilizar para optimizar su consulta.
Es de recalcar que nadie nos garantiza que el almacén sepa hacer uso
de esa información para optimizar el acceso a los datos. Simplemente
ponemos a disposición del almacén esa información por si le puede ser
de utilidad. Y que si especificamos información de contexto, los datos
que devuelve la consulta no serán rigurosos.
En este apartado veremos conceptos como:
- inserción de nuevos fenómenos en un almacén
- modificación de fenómenos ya existentes en un almacén
- eliminación de fenómenos de un almacén.
- reglas de validación.
El almacén dispone de servicios que nos permiten
la modificación de los datos. Para poder modificar los
datos, lo primero que deberemos hacer es notificar al
almacén que vamos a modificar datos suyos. Y, al
igual que le notificamos que queremos modificarlos,
tendremos que informarle cuando hayamos terminado
de hacerlo. Una vez informamos al almacén que vamos a
modificar los datos, este entra en modo modificación
de datos, y permanecerá en ese modo hasta que le
digamos que hemos terminado.
Antes de seguir adelante vamos ha hacer un inciso sobre
el modo de operación en el que se puede encontrar un FeatureStore .
Estos puede ser:
- Modo consulta, MODE_QUERY. Es el modo por defecto
para un almacén. Cuando es creado uno se queda en
este modo. En este modo solo se pueden realizar operaciones
de consulta, no están permitidas la ejecución de operaciones
de edición. En caso de intentar ejecutar alguna se producirá
una excepción NeedEditingModeException .
- Modo edición, MODE_FULLEDIT. En este modo se permiten
todos los comandos de edición. Se dispondrá de servicios
de hacer/rehacer operaciones y las operaciones de edición
no se consolidaran hasta que se termine la edición.
- Modo añadir, MODE_APPEND. Es un modo de edición limitado.
No están habilitados los servicios de hacer/rehacer, y las
únicas acciones relacionadas con edición que están permitidas
son las de insert de un nuevo fenómeno y finishEditing.
La consolidación de los cambios queda a criterio del proveedor
de datos final si se realiza cada vez que se ejecute la
acción insert o al ejecutarse la acción finishediting.
No todos los proveedores de datos soportan este modo. En
caso de que el proveedor no lo soporte y sea solicitado,
el almacén entrara automáticamente en modo edición.
Hay que destacar que el Modo edición está disponible para todos los
almacenes. Ahora bien, es posible de que el almacén no tenga
permitida la persistencia de los datos (ver método allowWrite) por
lo que, al finalizar la edición podemos obtener una excepción dependiendo
si podemos escribir en el almacén o si hemos realizado o no cambios mayores.
Ahora veamos cuales son las acciones, relacionadas con
edición que nos permite realizar el almacén de fenómenos:
- allowWrite. Esta acción nos informa si el almacén
en cuestión es susceptible de escribir las modificaciones
sobre el soporte de almacenamiento que tenga asociado.
- edit. Esta acción es con la que le indicamos
al almacén que queremos entrar en modo modificación
de datos. Esta acción sin ningún otro parámetro mas
entrara en modo edición, de otra forma habrá que indicar como
parámetro en que modo de edición se quiere entrar.
- cancelEditing. Esta acción nos permite indicarle al
almacén que queremos cancelar todas las modificaciones
y pasar a modo normal o de consulta.
- finishEditing. Con esta acción le indicamos al almacén
que de por terminadas las acciones de modificación, consolide
los cambios y salga del modo de modificación de datos.
- isEditing. Nos informa si el almacén se
encuentra en modo modificación de datos o
no.
- isAppending. Nos informa si el almacén se
encuentra en modo adición de datos o
no.
- undo. Una vez estamos en modo modificación de datos
y ya hemos realizado algunas modificaciones sobre el
almacén, esta acción nos permite ir deshaciendo una
a una las modificaciones realizadas.
- redo. Cuando hemos invocado al método undo, podemos
volver a indicarle al almacén que de por valida la ultima
acción cancelada mediante la acción undo invocando a
este método. Podremos ir rehaciendo todas las acciones
canceladas con el método undo invocando sucesivamente al
método redo
- insert. Inserta un fenómeno en el almacén.
- update. Actualizar un fenómeno del almacén.
- delete. Elimina un fenómeno del almacén.
- createNewFeature. Al invocar a este método con un FeatureType ,
el almacén creara un nuevo fenómeno con la estructura
indicada en el FeatureType pasado. Además podemos indicar
si queremos o no que se el nuevo fenómeno se rellene con los
valores por defecto para ese tipo.
- isAppendModeSupported, nos informa si el almacén
soporta el modo de edición añadir nuevos fenómenos.
Este modo de edición presenta solo un subconjunto de las
funciones de edición del almacén y esta orientado a la
creación en modo no interactivo de nuevos juegos de datos.
- beginEditingGroup, endEditingGroup, que permiten
agrupar un conjunto de instrucciones de edición como si
de una sola se tratase a efectos de las acciones hacer/rehacer.
Además de las acciones del almacén que nos permiten realizar
modificaciones en los datos, conviene repasar cuales son las
acciones de los fenómenos que nos van a permitir modificar sus
datos. En principio, un Feature es de solo lectura, es decir,
solo podemos realizar operaciones de consulta sobre el. Si queremos
modificar un Feature tendremos que obtener un EditableFeature a
partir de el, el cual ya tendrá acciones asociadas a modificar sus
datos. Para obtener un EditableFeature usaremos el método getEditable
del Feature . El método createNewFeature ya devuelve un EditableFeature .
El EditableFeature se comporta como un Feature añadiéndole
una serie de acciones mas. Las mas importantes serian:
- set para permitirnos modificar los valores de los
atributos.
- setString, setInt, setGeometry para permitirnos modificar los valores de los
atributos usando tipos específicos.
- getNotEditableCopy, que nos devolverá una copia no modificable
del EditableFeature .
Veamos ahora un ejemplo simple de como usar estas acciones para
insertar un nuevo fenómeno dentro el almacén. Vamos a suponer que
disponemos de un archivo dbf que contiene dos campos, un campo
NOMBRE y otro TIPO de tipo cadena. La apertura del almacén
se realiza tal como hemos hecho para acceder en modo lectura.
Una vez tenemos una instancia de almacén, el código para
añadir un nuevo fenómeno seria:
store = manager.createStore(parameters);
store.edit();
EditableFeature feature = store.createNewFeature();
feature.set("NOMBRE", "Burjasot");
feature.set("TIPO", "MUNICIPIO");
store.insert(feature);
store.finishEditing();
store.dispose();
Los pasos serian los siguientes:
- comunicar al almacén que vamos a entrar en
modo modificación de datos.
- Pedirle al almacén que nos suministre un fenómeno
vació de contenido y con la estructura de los
fenómenos del almacén.
- Asignamos los nuevos valores a los atributos.
- Insertamos en el almacén la nueva feature.
- Y por ultimo le comunicamos al almacén que
hemos terminado de hacer modificaciones sobre el.
Tenemos que tener en cuenta que asta que no se ejecute la
acción finishEditing sobre el almacén, los cambios
que se hayan realizados no serán visibles para otros
usuarios o aplicaciones que estén accediendo al mismo
almacén.
Una cuestión importante a tener en cuenta relacionada con la
actualización o borrado de datos de un almacén es que pasa con
los conjuntos de datos que se han obtenido de ese almacén y sobre
los que se puede estar trabajando desde otros puntos de la aplicación.
En principio el almacén invalida todos los FeatureSet que
se han obtenido de el tras una operación de modificación o
borrado en el almacén. De forma que tras esta operación cualquier
intento de acceder a un FeatureSet obtenido con anterioridad producirá
una excepción de tiempo de ejecución ConcurrentModificationException .
Para evitar que mientras estemos recorriendo un FeatureSet y realizando
actualización o borrados en él este quede invalidado, usaremos los
métodos delete, insert y update de FeatureSet o el método remove
del iterador asociado al FeatureSet.
Veamos como podríamos hacer para modificar los fenómenos
de nuestro almacén en dbf. Supongamos que queremos
cambiar el valor del atributo TIPO para el fenómeno
que tiene en el atributo NOMBRE el valor "Burjasot".
store.edit();
EditableFeature feature;
FeatureQuery query = store.createFeatureQuery();
query.setFilter( manager.createExpresion("NOMBRE = 'Burjasot'") );
features = store.getFeatureSet(query);
Iterator it = features.iterator();
while( it.hasNext() ) {
feature = ((Feature)it.next()).getEditable();
feature.set("TIPO", "Municipio");
features.update(feature);
}
features.dispose();
store.finishEditing();
store.dispose();
- Filtramos sobre el almacén para obtener solo los fenómenos
que queremos.
- Informamos al almacén que queremos realizar modificaciones sobre
el.
- para cada fenómeno recuperado, le pedimos un EditableFeature ,
y lo modificamos.
- después pedimos al FeatureSet que actualice el fenómeno
en el almacén
- Y por ultimo le decimos al almacén que hemos terminado
de realizar modificaciones.
Si quisiésemos eliminar los fenómenos que tienen como NOMBRE
el valor "Burjasot" seria similar a la actualización pero
invocando al método delete en lugar de update:
store.edit();
FeatureQuery query = store.createFeatureQuery();
query.setFilter( manager.createExpresion("NOMBRE = 'Burjasot'") );
features = store.getFeatureSet(query);
Iterator it = features.iterator();
while( it.hasNext() ) {
it.next();
it.remove();
}
features.dispose();
store.finishEditing();
store.dispose();
Relacionado con la modificación e inserción de fenómenos en un
almacén de datos, esta la posibilidad de asignar reglas de validación
a los fenómenos de un almacén. Las reglas de validación se asignan
a cada tipo de fenómeno del almacén, es decir es el FeatureType
el que controla que reglas hay que aplicar a los fenómenos de su tipo.
Podemos invocar manualmente a las reglas de validación sobre un fenómeno
mediante la acción validate de Feature o sobre todos fenómenos del
almacén mediante la acción validateFeatures del FeatureStore .
A la hora de crear una regla de validación tendremos que tener en cuenta que
una regla de validación puede ejecutarse...
- Cuando se inserte o actualice un fenómeno en el almacén de datos
- Al finalizar la edición se ejecutan las reglas de validación de
todas los fenómenos del almacén.
- En ambos casos.
Según nos interese tendremos que indicar cuando queremos que se ejecute
la regla de validación.
Vamos a crear una regla de validación que se encarga de que
el sentido de los segmentos de los polígonos sea el adecuado.
Para ello deberemos crear una clase que implemente el interface FeatureRule .
Este interface nos obliga a suministrar los siguientes métodos:
- getName, con el nombre que le queramos dar a la regla de
validación.
- getDescription, opcionalmente podemos incluir una descripción de
unas lineas asociada a la regla de validación.
- checkAtUpdate, devolverá el valor de cierto si la regla debe ser
ejecutada en el momento de realizarse una modificación o inserción de un
nuevo fenómeno.
- checkAtFinishEdition, devolverá el valor cierto si la regla debe
ejecutarse sobre todos los fenómenos del almacén al finalizar la
edición.
- validate, que ejecutara la validación sobre el fenómeno que reciba
como parámetro. En caso de que no pase la regla de validación lanzara
una excepción.
Además de este interface, existe una clase abstract AbstractFeatureRule
que nos resuelve la gestión de cuando ha de ejecutarse, el nombre y la descripción
de la regla, dejando únicamente pendiente le implementación del método
validate.
FIXME:
El ejemplo siguiente esta asumiendo que el validate solo
va a ser llamado estando en modo edición. Habría que comprobar
esto antes de invocar al update del store.
Veamos como quedaría nuestro ejemplo:
public class FeatureRulePolygon extends AbstractFeatureRule {
public FeatureRulePolygon() {
super("RulePolygon", "Ensure orientation of geometry");
}
public void validate(Feature feature, FeatureStore store)
throws DataException {
try {
Geometry geom = feature.getDefaultGeometry();
GeneralPathX gp = new GeneralPathX();
gp.append(geom.getPathIterator(null, Converter.FLATNESS), true);
if (gp.isClosed()) {
if (gp.isCCW()) {
gp.flip();
GeometryFactory geomFactory = GeometryManager.getInstance()
.getGeometryFactory();
geom = geomFactory.createPolygon2D(gp);
EditableFeature editable = feature.getEditable();
editable.setDefaultGeometry(geom);
store.update(editable);
}
}
} catch (Exception e) {
throw new FeatureRulePolygonException(e, store.getName());
}
}
public class FeatureRulePolygonException extends DataException {
private static final long serialVersionUID = -3014970171661713021L;
private final static String MESSAGE_FORMAT = "Can't apply rule in store %(store)s.";
private final static String MESSAGE_KEY = "_FeatureRulePolygonException";
public FeatureRulePolygonException(Throwable cause, String store) {
super(MESSAGE_FORMAT, cause, MESSAGE_KEY, serialVersionUID);
this.setValue("store", store);
}
}
}
Podemos observar que el método validate recibe la feature a validar
y el almacén donde esta vive, y se limita a coger la geometría
de la feature, procesarla y si es preciso actualizar el feature con
los nuevos valores.
Durante la validación de una regla podremos actualizar el fenómeno que
estamos tratando, pero no deberemos cambiar la estructura del almacén, es
decir, no deberemos realizar ninguna operación que modifique los FeatureType
de este.
Si durante el proceso de validación de fenómenos que se realiza al
finalizar la edición alguien modifica algún fenómeno, se abortara el
proceso, quedando a decisión del que invoco a finishEdition comprobar
si fue por una modificación de los fenómenos mientras se procesaban para
volver a lanzar la operación.
Nota:
Aquí habría que poner un ejemplo de como hacer esto.
Para consultar la estructura de los fenómenos de un almacén, FeatureStore,
dispone de dos acciones:
Las primeras preguntas que tendemos ha hacernos cuando vemos estos métodos
son:
- ¿ qué es eso del tipo de fenómeno por defecto ?
- ¿ Por qué una lista de tipos de fenómenos ?
Las dos preguntas van estrechamente ligadas.
Normalmente estamos acostumbrados a encontrarnos almacenes como
ficheros shapes, dxf, dgn o bases de datos como postgreSQL en los que
los fenómenos tienen una estructura común a todo el almacén. Sin embargo
hay escenarios en los que eso puede no ser así. Por ejemplo, podemos encontrarnos
un fichero GML en el que los fenómenos tienen dos, tres o mas estructuras distintas
a lo largo el fichero. La forma de consultar cual es la estructura de los
fenómenos seria a través del método getFeatureTypes , que nos dará una lista
con un FeatureType por cada tipo de fenómeno del almacén.
Como durante mucho tiempo hemos manejado almacenes que solo soportan un tipo
de fenómeno, se ha introducido el método getDefaultFeatureType en el almacén para
facilitar el acceso al FeatureType cuando solo existe un tipo de fenómeno.
¿ Y qué pasa si invocamos al getDefaultFeatureType sobre un almacén con varios
tipos de fenómenos ?
Este nos devolverá un FeatureType de forma arbitraria dependiendo del tipo de
almacén con el que estemos trabajando.
En general, a no ser que estemos seguros de que solo hay un tipo de fenómenos en el
almacén deberemos usar getFeatureTypes para acceder a la estructura de estos.
Siempre podemos consultar el size de la lista para determinar cuantos tipos de
fenómeno tenemos.
Una vez hemos conseguido un FeatureType, podemos pensar en el como en una lista de
descriptores de los atributos del fenómeno, disponiendo de un método size que nos
dice cuantos atributos tiene el fenómeno que describe, un método get que nos
devolverá un FeatureAttributeDescriptor, por nombre o índice, o un iterador sobre
estos.
Veamos cuales son las principales acciones que podemos encontrarnos en un FeatureType
que nos permitan interrogarle para saber de la estructura
del fenómeno:
- size, nos devuelve el numero de atributos que tiene el fenómeno.
- get, que dándole un nombre o un índice de atributo nos devolverá
un descripción de las propiedades del atributo, FeatureAttributeDescriptor .
- getIndex, que dándole un nombre de atributo nos devuelve el índice
de este.
- getDefaultGeometryAttributeName, nos da el nombre del atributo que es
la geometría por defecto de este almacén. Normalmente gvSIG pintará esta
geometría cuando tenga que obtener una representación gráfica del almacén.
- getDefaultGeometryAttributeIndex, nos da el índice del atributo que es
la geometría por defecto de este almacén.
- getDefaultSRS. Nos devuelve la cadena que representa al SRS de la geometría
por defecto.
- getSRSs. Un fenómeno puede contener mas de un atributo de tipo geometría,
y cada atributo de tipo geometría puede tener un SRS diferente. Este método
nos devolverá una lista con los SRSs de todos los atributos de tipo geometría.
- iterator. Nos devuelve un iterador sobre los descriptores de atributos del
fenómeno.
Conviene también dar un vistazo, aunque sea superficial, a los principales métodos
u operaciones que podemos encontrar en el FeatureAttributeDescriptor.
- getName, que nos informara sobre el nombre del atributo.
- getDataType y getDataTypeName, que nos dirá de que tipo son los
datos asociados al atributo. La lista de tipos soportados están definidos
en el interface DataTypes .
- getDefaultValue, nos dirá cual es el valor por defecto del atributo.
- getIndex, nos dirá el índice numérico asociado al atributo.
- getSize, para los tipos de datos que lo precisen , por ejemplo las
cadenas, nos informa de cual es su tamaño.
- getEvaluator, que nos devolverá una instancia del Evaluator asociado
al atributo, en caso de que este sea un atributo calculado.
- allowNull, nos informa de si ese atributo permite o no valores nulos.
- isPrimaryKey, nos dirá si ese atributo forma parte de la clave
primaria que usa el proveedor de datos para identificar al fenómeno.
- isReadOnly, que nos dirá si ese atributo puede ser actualizado o no.
Veamos ahora un pequeño ejemplo en el que se nos muestra como podemos obtener
el nombre de los atributos y su tipo de datos asociados a un FeatureType.
FeatureType featureType = store.getDefaultFeatureType();
Iterator it = featureType.iterator();
while( it.hasNext() ) {
attribute = (FeatureAttributeDescriptor)it.next();
System.out.print(attribute.getDataTypeName();
if( attribute.getSize() > 1 ) {
System.out.print("["+attribute.getSize()+"]");
}
System.out.print(" " + attribute.getName() );
Evaluator eval = attribute.getEvaluator();
if( eval != null ) {
System.out.print(attribute.getName()+", "+attribute.getDataTypeName()+" -- Calculado "+ eval.getCQL());
}
System.out.println();
}
En otros apartados hemos estado viendo que servicios nos proporciona
DAL para el acceso a los datos tabulares. Normalmente estos servicios
se ofrecen por el FeatureStore. Sin embargo los servicios relacionados
con la creación física del almacén, no nos los da el FeatureStore. Estos
servicios forman parte de los servicios que ofrece el DataServerExplorer.
El DataServerExplorer reúne los servicios relacionados con la exploración
de un servidor de datos junto de los de creación de nuevos almacenes en
el servidor. Vamos a ver aquí la parte de añadir un nuevo almacén a un
servidor de datos, en este caso un sistema de ficheros, el FilesystemExplorer.
Un DataServerExplorer dispone para estas tareas de los métodos:
- getAddParameters. Este, dado un nombre de almacén registrado,
nos devolverá un DataParameters especializado con los parámetros
que precisa ese el almacén indicado para ser creado.
- add, que a partir del DataParameters indicado se encargara de
crear el nuevo almacén en el servidor.
Veamos un ejemplo de creación de un almacén de tipo dbf. Crearemos
un fichero prueba.dbf en la carpeta /data. El fichero dbf
contendrá los campos:
- NOMBRE, de tipo STRING de 100 caracteres.
- MUNICIPIO, de tipo STRING de 100 caracteres.
- POBLACION, de tipo LONG.
- AREA, de tipo DOUBLE.
Para esto tendremos que hacer:
- Crearemos un DataServerExplorer de tipo FilesystemExplorer, indicando
que el path inicial sobre el que ha de trabajar es /data.
- Le pediremos al DataServerExplorer una instancia de parámetros adecuada
para crear un fichero dbf.
- Indicaremos en esos parámetros el nombre del fichero a crear, sin ruta,
ya que utilizara la ruta corriente del DataServerExplorer para ello.
- Le pediremos los parámetros la instancia del FeatureType que se va a
utilizar para la creación del dbf. Este sera de tipo EditableFeatureType.
- Añadiremos al FeatureType los atributos que queremos que tenga nuestro
dbf
- Y por ultimo le indicaremos al DataServerExplorer que añada la nueva
fuente de datos de la que hemos configurado sus parámetros.
Veamos como queda todo esto junto:
DataExplorerParameters eparams = manager.createServerExplorerParameters("FilesystemExplorer");
eparams.setDynValue("initialpath","/data");
DataServerExplorer serverExplorer = manager.createServerExplorer(eparams);
NewFeatureStoreParameters sparams = (NewFeatureStoreParameters)serverExplorer.getAddParameters("DBF");
sparams.setDynValue("dbffilename","prueba.dbf");
EditableFeatureType featureType = (EditableFeatureType)sparams.getDefaultFeatureType();
featureType.add("NOMBRE", DataTypes.STRING,100);
featureType.add("MUNICIPIO", DataTypes.STRING,100);
featureType.add("POBLACION", DataTypes.LONG);
featureType.add("AREA", DataTypes.DOUBLE);
serverExplorer.add(sparams);
En otros apartados hemos estado viendo las operaciones o servicios que ofrece el
FeatureType de cara a consultar su estructura. Vamos a repasar los servicios que
añade el EditableFeatureType a este de cara a modificar esta:
- add. Nos permite añadir nuevos atributos a la descripción del fenómeno.
Le indicaremos el nombre del nuevo atributo y el tipo y nos devolverá una
instancia de EditableFeatureAttributeDescriptor, que es similar a
FeatureAttributeDescriptor, pero añadiendo operaciones que permiten
modificar las propiedades del atributo.
- getNotEditableCopy, que nos devuelve una copia de el mismo no editable,
es decir un FeatureType.
- getSource, nos devuelve una referencia al FeatureType del que creamos
esta versión editable. Si el EditableFeatureType no se creo a partir de
un EditableFeature devolverá null.
- remove, que nos permite eliminar una descripción de atributo.
- setDefaultGeometryAttributeName, que nos permite indicar cual es el
nombre del atributo que contiene la geometría a usar como geometría
por defecto del fenómeno.
Veamos algunos detalles interesantes del método add. Este método esta sobrecargado
y presenta tres variantes:
- add(String name, int type). Se trata de la versión simple, y crea, añade y
devuelbe un nuevo atributo del nombre y tipo indicado.
- add(String name, int type, int size). Se comporta de forma similar al anterior,
pero permite fijar el tamaño. Es útil con el tipo STRING para especificar
de forma cómoda el tamaño de este.
- add(String name, int type, Evaluator eval). Con este podemos añadir
nuevos atributos cuyos valores se calculen usando el evaluador indicado.
En otro apartado se vera esto con mas detalle (Soporte para atributos calculados).
En el apartado consultando la estructura de un almacén vimos como podemos consultar
la estructura de un almacén de datos. Esta venia descrita por el FeatureType y el
FeatureAttributeDescriptor. En el apartado creación de un nuevo almacén vimos como
podemos crear un nuevo almacén de datos y los equivalentes al FeatureType y
FeatureAttributeDescriptor que nos permiten modificarlos, el EditableFeatureType y
el EditableFeatureAttributeDescriptor . En general estas dos últimos interfaces
contienen todo lo que podemos necesitar no solo para crear nuevos almacenes de datos
sino para modificar los ya existentes.
Igual que para modificar un fenómeno de un almacén, para modificar la estructura de
estos tenemos que estar en modo edición. Luego solo tenemos que limitarnos a obtener el
FeatureType que queremos modificar; cambiar, añadir o borrar atributos sobre el y actualizar
el almacén con los cambios mediante el método update.
Veamos esto con un simple ejemplo.
En creación de un nuevo almacén creamos un almacén de datos con dos campos, MUNICIPIO
y NOMBRE de tipo cadena y un tamaño de 100 caracteres. Vamos a cambiar el tamaño de
estos atributos a 50 caracteres.
store.edit();
FeatureType featureType = store.getDefaultFeatureType();
EditableFeatureType editableFeatureType = featureType.getEditable();
editableFeatureType.getAttributeDescriptor("MUNICIPIO").setSize(50);
editableFeatureType.getAttributeDescriptor("NOMBRE").setSize(50);
store.update(editableFeatureType);
store.finishEdition()
Los pasos realizados son:
- Iniciar edición.
- Obtener el FeatureType asociado al almacén.
- Obtener una versión editable del FeatureType.
- Acceder a los descriptores de los atributos y cambiarles
el size a 50.
- Actualizar el almacén con la nueva definición. A partir de este
momento, las acciones sobre el almacén tendrán en cuenta la nueva
definición, aunque los cambios no se han consolidado en disco.
- Por ultimo, terminaremos la edición, quedando consolidados en
disco los cambios de estructura del almacén.
Sobre la selección de datos de un almacén, en este apartado se trata:
- Cómo acceder a la selección de un almacén.
- Cómo cambiar la selección de un almacén por otra.
- Operaciones que se pueden realizar con la selección.
- Recepción de eventos de selección.
El acceso a la selección de un almacén se realiza a través del método getSelection del almacén:
FeatureSelection selection = store.getFeatureSelection();
Si no queremos trabajar directamente con la selección del almacén, podemos crear una selección nueva a través del propio almacén:
FeatureSelection selection2 = store.createFeatureSelection();
Si queremos sustituir la selección del almacén por otra bastará con establecerla:
store.setSelection(selection2);
Una vez obtenida la selección, a través de ella podemos realizar las siguientes operaciones:
- Seleccionar o de seleccionar un fenómeno, un FeatureSet o todos los fenómenos del almacén.
- Averiguar si un fenómeno está seleccionado.
- Invertir la selección.
- Obtener los fenómenos seleccionados o de seleccionados, ya que el FeatureSelection es, a su vez, un FeatureSet.
Ej:
Feature feature = ...
// Seleccionamos un fenómeno
selection.select(feature);
// Devolverá true
selection.isSelected(feature);
// Invertimos la selección
selection.reverse();
// Devolverá false
selection.isSelected(feature);
// Seleccionamos todos
selection.selectAll();
// Devolverá true
selection.isSelected(feature);
// Deseleccionamos el fenómeno
selection.deselect(feature);
// Devolverá false
selection.isSelected(feature);
Si lo que queremos es recibir eventos sobre cambios en la selección, podemos suscribirnos como Observer al almacén directamente, de forma que recibiremos, entre otros eventos, el evento DataStoreNotification.SELECTION_CHANGE.
Por ejemplo, la tabla que muestra una lista de fenómenos, debe repintarse para actualizar las filas seleccionadas cuando cambia la selección en el almacén correspondiente. Para ello implementa Observer y se registra como tal en el almacén. Su método update es como sigue:
public void update(Observable observable, Object notification) {
if (notification instanceof FeatureStoreNotification) {
FeatureStoreNotification fsNotification = (FeatureStoreNotification) notification;
String type = fsNotification.getType();
// If the selection has changed, repaint the table to show the new
// selected rows
if (FeatureStoreNotification.SELECTION_CHANGE.equals(type)) {
repaint();
}
}
}
Nota:
En relación a la gestión de bloqueos están definidos los interfaces
que forman parte del API pero no se ha realizado aun ninguna implementación
de estos.Es posible que sufra algunas variaciones
tras su implementación.
En ocasiones puede ser interesante disponer de funciones de bloqueo de
fenómenos sobre un almacén para evitar que desde otros puestos modifiquen
los datos sobre los que vamos a trabajar en un momento dado. Para dar
servicio a esta necesidad, el FeatureStore dispone de dos métodos:
- isLocksSupported, que nos informa de si ese almacén soporta
gestión de bloqueos.
- getLocks, que actúa a modo de conjunto de fenómenos que tengo
bloqueados en un momento dado en el almacén. En caso de que el
almacén no soporte bloqueos, este método devolverá null.
Cuando un almacén soporta la gestión de bloqueos, el método getLocks nos
devolverá un FeatureLocks. Esta clase se encargara de llevar la cuenta de
los bloqueos que se establecen así como de su tiempo de vigencia. Los bloqueos
se establecen en grupos de fenómenos, y a cada grupo de fenómenos que se
bloquea se le asigna un tiempo de vigencia para ese bloqueo. Para bloquear
fenómenos tendremos los métodos:
- lock y lockAll, que añade un fenómeno o conjunto de estos al
grupo de fenómenos a bloquear.
- unlock y unlockAll, que elimina un fenómeno o conjunto de estos del
grupo de fenómenos a bloquear.
- setDefaultTimeout y getDefaultTimeout, que permiten fijar el tiempo
de vigencia de los bloqueos.
- apply, que crea un grupo de bloqueos con los bloqueos indicados mediante
las operaciones lock con el tiempo de vigencia por defecto y aplica los
bloqueos en el almacén.
Además dispondremos de operaciones para consultar si un fenómeno esta
bloqueado, así como para consultar los grupos de bloqueos que se han
establecido.
- getGroups, que nos devuelve un iterador sobre los grupos
de bloqueos establecidos. Cada grupo de bloqueos esta
representado por la clase FeatureLocksGroup .
- getGroupsCount, que nos dice cuantos grupos de bloqueos
hay.
- isLocked, que nos informa sobre si un fenómeno esta bloqueado
independientemente de en que grupo de bloqueo se bloqueo.
- getLocksCount, que nos informa de cuantos fenómenos tenemos
bloqueados.
- getLocks, que nos devuelve un iterador sobre todos los
fenómenos bloqueados.
También es interesante tener en cuenta que FeatureLocks implementa
Observable , de forma que podemos registrarnos a cambios en el. Los
cambios que podemos observar son:
- Se ha aplicado un nuevo grupo de bloqueos.
- Un grupo de bloqueos a caducado.
- Un grupo de bloqueos se ha liberado.
Los principales métodos u operaciones que podemos encontrar en un
grupo de bloqueos, FeatureLocksGroup, son:
- getTimeout, tiempo de caducidad asignado al bloqueo.
- XXX, que nos devuelve el tiempo en milisegundos que resta
asta que el bloqueo caduque.
- unlock, libera todos los bloqueos del grupo, haciendo
desaparecer a este.
- iterator, que nos devuelve los fenómenos, Feature, que se
encuentran bloqueados en ese grupo.
- getLocksCount, que nos informa sobre cuantos fenómenos hay
bloqueados en ese grupo de bloqueos.
- isLocked, que nos informa si un fenómeno esta bloqueado
en este grupo de bloqueos.
Hasta ahora hemos estado viendo una serie de servicios que un almacén de datos,
a través del FeatureStore ofrece sin importarnos qué tipo de almacén de datos
sea. Son servicios que ofrecen de forma estándar todos los almacenes de datos
tabulares. Sin embargo, podemos encontrarnos que para algún tipo especial de
almacén de datos este ofrezca algún servicio extra, bien porque el propio
proveedor de datos lo suministra, bien porque alguna librería externa suministra
ese servicio y lo ofrece a través del propio almacén.
Cuando nos referimos a operaciones, nos referimos a estos servicios extra que
pueden estar asociados a un almacén especifico.
Para acceder a estas operaciones lo hacemos a través de la utilidad DynObject que
presenta la librería libTools (org.gvsig.tools) . La clase FeatureStore implementa el interface DynObject
usando el nombre de clase dinámica FeatureStore. Llegados a este punto es recomendable
que repase la documentación de esta utilidad antes de seguir (libtools - DynObject),
aunque si no lo hace
intentaremos dar las descripciones necesarias para que pueda entender el uso
que se hace de ella desde el FeatureStore.
El FeatureStore por implementar el interface DynObject dispone de un método, getDynClass,
que nos devolverá un objeto DynClass. Este contiene una definición de métodos y atributos
añadidos dinámicamente a la instancia de nuestro almacén. Podemos usar ese DynClass para
interrogar por los métodos añadidos de la siguiente forma:
DynMethod[] methods = store.getDynClass().getDynMethods();
for( int i=0; i<methods.length; i++ ) {
System.out.print("method '"+ methods[i].getName() + "'");
if( methods[i].getDescription() != null ) {
System.out.print(", "+ methods[i].getDescription());
}
System.out.println(".");
}
Con este ejemplo obtendremos un listado de métodos u operaciones que han sido añadidos
a nuestro almacén, con su nombre y su descripción si la tuviese.
¿ Y cómo invocamos a esas operaciones o métodos ?
Supongamos que sabemos que hay almacenes que pueden suministrar una leyenda
específica para sus datos mediante una operación getLegend. Podemos utilizar
el siguiente código para invocar a esa operación y obtener la leyenda en caso
de que nuestro almacén lo soporte.
if( store.getDynClass().getDynMethod("getLegend")!= null ) {
ILegend Legend = (ILegend)store.invokeDynMethod("getLegend", null);
}
De cara al uso de las operaciones especificas que puede presentar un almacén de
datos, estas son las principales operaciones que vamos a tener que realizar:
- consultar de que operaciones disponemos.
- invocar a alguna de esas operaciones.
Si queremos saber más sobre cómo crear sus propias operaciones consulte el
apartado Servicios asociados al proveedor de datos, SPI.
En este apartado veremos:
- Como añadir un atributo calculado simple, basado
en una expresión de cadena.
- Algunas consideraciones sobre la edición y los
atributos calculados.
- Como crear un campo calculado complejo que requiera
un evaluador especializado.
En el apartado creación de un nuevo almacén vimos como crear un
alamcén en formato dbf en el que teníamos un atributo POBLACION y
otro AREA.
Puede ser interesante disponer del valor de densidad de población en
ese mismo almacén. En lugar de añadirle un nuevo atributo con el valor de
la densidad de población podemos añadirle un atributo que calcule la
densidad de población en función de los campos AREA y POBLACION.
Veamos como podríamos hacer esto.
store.edit();
FeatureType featureType = store.getDefaultFeatureType();
EditableFeatureType editableFeatureType = featureType.getEditable();
editableFeatureType.add("DENSIDAD_POBLACION",
DataTypes.DOUBLE,
manager.createExpresion("POBLACION / AREA")
);
store.update(editableFeatureType);
store.finishEditing();
Para añadir el nuevo atributo, deberemos añadir a la descripción del
fenómeno del almacén un nuevo atributo. Veamos una breve explicación
de los pasos que hemos seguido para realizar esta operación:
- Puesto que vamos a realizar una modificación sobre
el almacén, deberemos asegurarnos que este se encuentra
en modo edición.
- Invocaremos a getDefaultFeatureType para obtener la descripción
de los fenómenos del almacén. Una vez dispongamos
de el, obtendremos una versión editable de este, ya que el que nos
devuelve getDefaultFeatureType es de solo consulta.
- Invocaremos a su método add para añadirle el nuevo atributo.
a este le indicaremos:
- El nombre del atributo a añadir, DENSIDAD_POBLACION.
- El tipo de datos asociado al atributo, TYPE_DOUBLE.
- Un evaluador que resuelva la expresión que deseamos.
El DataManager nos suministrara un constructor por
defecto para evaluadores de expresiones mediante su método
createExpresion, asi que le diremos que la expresión que
deseamos que tenga sera "POBLACION / AREA".
- invocaremos al método update del almacén, FeatureStore,
con el FeatureType modificado para que se apliquen los cambios.
- Por ultimo, si hemos iniciado la edición para realizar esta
operación la terminaremos.
Hay que tener en cuenta una consideración respecto a la adición de
campos calculados a un almacén. Para realizar esta operación es preciso
entrar en edición del almacén y finalizarla al terminar de añadir
los campos calculados. Sin embargo, la operación de inserción de
campos calculados no afecta a los datos del almacén ni a la
estructura de este. Es decir, al finalizar al edición no se realiza
ninguna modificación sobre el almacén físico de datos. Los cambios
quedan únicamente en la definición en memoria de este. Se trata de
una edición que provoca unos cambios ligeros o suaves por decirlo
de alguna manera. Cuando la edición provoca cambios de este tipo, no
precisa que el almacén soporte escritura. Es decir podemos hacer este
tipo de operaciones de edición sobre almacenes aunque la invocación a
allowWrite sobre el almacén indique que no esta soportada la escritura.
Veamos ahora un ejemplo algo mas complejo de atributo calculado.
En el ejemplo anterior utilizábamos el evaluador de expresiones que
suministra por defecto el DataManager. Ahora bien, puede suceder que
este evaluador de expresiones no nos de la capacidad de calculo que
necesitemos para nuestro atributo. En estos casos podemos crear
nuestro propio evaluador a medida de las operaciones que deseemos.
Veamos esto con un ejemplo.
Supongamos que tenemos un fichero dbf en el que tenemos dos atributos,
X e Y con las coordenadas x e y de un punto, y quisiésemos representar
esos puntos como tales en lugar de como dos simples números. Podríamos
añadir un atributo calculado que nos devolviese una geometría construida
a partir de los valores de los campos X e Y. Veamos el ejemplo, por
un lado necesitaremos crear nuestro evaluador:
class XY2Geometry extends AbstractEvaluator {
private String xname;
private String yname;
private GeometryManager geomManager;
public XY2Geometry initialize(String xname, String yname) {
this.xname = xname;
this.yname = yname;
geomManager = GeometryLocator.getGeometryManager();
return this;
}
public Object evaluate(EvaluatorData data) throws EvaluatorException {
Double x = (Double) data.getDataValue(this.xname);
Double y = (Double) data.getDataValue(this.yname);
Geometry geom;
try {
geom = geomManager.createPoint(x.doubleValue(), y
.doubleValue(), Geometry.SUBTYPES.GEOM2D);
} catch (CreateGeometryException e) {
throw new EvaluatorException(e);
}
return geom;
}
public String getName() {
return "XY2Geometry";
}
}
La clase abstracta AbstractEvaluator, nos deja dos métodos por implementar:
- getName, que deberá devolver un nombre descriptivo de la operación
que vallamos a hacer.
- evaluate, que recibe un EvaluatorData, en el que recibiremos los
valores del resto de atributos del fenómeno. Este método deberá ser
el encargado de realizar los cálculos y devolver el resultado de estos.
En nuestro caso, obtendrá los valores de los campos x e y, y con ellos
construirá una geometría de tipo punto que sera lo que devuelva.
Además de estos métodos, le hemos añadido un método initialize en el
que le pasamos los parámetros que necesita para realizar correctamente los
cálculos. Es recomendable disponer de un método de inicialización separado
del constructor ya que eso nos puede facilitar las tareas de serialización
del objeto en caso de que lo necesitemos.
Y una vez dispongamos de un evaluador adecuado podemos añadir ya
nuestro atributo calculado al almacén:
store.edit();
FeatureType featureType = store.getDefaultFeatureType();
EditableFeatureType editableFeatureType = featureType.getEditable();
editableFeatureType.add("GEOM",
DataTypes.GEOMETRY,
new XY2Geometry().initialize("X", "Y")
);
store.update(editableFeatureType);
store.finishEditing();
En este caso, a diferencia de nuestro ejemplo anterior sobre la densidad
de población, en la invocación al método add, le indicaremos:
- El nombre del nuevo atributo que añadimos, GEOM.
- Que su tipo de datos, en lugar de ser DOUBLE, ahora es
un GEOMETRY.
- Y que en lugar de invocar al DataManager para obtener un
evaluador de expresiones de cadena, construimos una instancia
de nuestro evaluador, XY2Geoemtry, la inicializamos con los
valores de los nombres de los campos que contienen la x e y, y
se la pasamos como el evaluador a usar en ese campo.
Cuando un almacén se pone en edición, internamente genera una pila de comandos con las operaciones que se van realizando. De esta forma, dichas operaciones se podrán deshacer o rehacer.
Para ello el almacén implementa el interfaz UndoRedoStack . Dicho interfaz aporta operaciones para:
- undo: deshacer la última o últimas operaciones realizadas.
Feature feature = store.createNewFeature();
feature.setAttribute("NOMBRE", "Burjasot");
feature.setAttribute("TIPO", "MUNICIPIO");
store.insert(feature);
// Se deshace la inserción de la feature anterior
store.undo();
- redo: volver a rehacer la última o últimas operaciones que han sido deshechas.
// Se vuelve a insertar la feature
store.redo();
- Ver si se puede seguir deshaciendo o rehaciendo operaciones.
if (store.canUndo()) {
System.out.println("Hay operaciones que se pueden deshacer");
}
- Obtener información acerca de la pila de operaciones que se pueden deshacer o rehacer.
De cada operación de la pila podemos obtener la siguiente información a través de la clase UndoRedoInfo:
- Una descripción de la operación.
- Fecha en la que se realizó la operación.
- El tipo de operación realizada, desde el punto de vista de cambios en los datos: inserción, modificación o borrado.
List infos = store.getRedoInfos();
for (int i = 0; i < infos.size(); i++) {
UndoRedoInfo info = (UndoRedoInfo)infos.get(i);
System.out.println("Operación " + i + ": " + info.getDescription());
}
En un almacén, algunas de las operaciones que se incorporarán a la pila en el modo de edición son:
- Inserción, modificación o borrado de fenómenos.
- Cambios en la estructura de los fenómenos.
- Cambios en la selección del almacén.
Hay que tener en cuenta que, una vez el almacén deja de estar en edición, la pila de comandos se descarta y los métodos del interfaz UndoRedoStack dejan de ser funcionales. Si volvemos a poner el almacén en edición, se creará una pila de comandos nueva.
En esta sección se dará una breve introducción a los siguientes conceptos
u operaciones sobre un almacén de datos:
- Alcance del soporte de índices
- Crear un índice sobre un almacén
- Obtener los índices de un almacén
- Obtener un índice por nombre
- Consultar un índice
- Coincidencia (match)
- Rango
- N elementos más cercanos
- N elementos más cercanos con tolerancia
- El índice
- Obtener su tipo de dato
- Obtener su nombre
- Obtener los atributos asociados
- Insertar un elemento
- Eliminar un elemento
- Algunas recomendaciones sobre el uso de índices
Alcance del soporte de índices
El soporte de índices que ofrece DAL actualmente consiste en la creación y manejo de índices temporales y locales a nivel de aplicación. El formato y ubicación real en que estos índices se almacenan depende de la librería que provee la implementación y no forma parte de las características del API.
Una vez se ha creado un índice sobre un almacén, éste lo utilizará para optimizar las consultas de forma automática cuando considere oportuno. A pesar de que este es el uso común, también se puede acceder a un índice manualmente y manipular su contenido.
Crear un índice sobre un almacén
Para crear un índice sobre un almacén de fenómenos, se utiliza el método createIndex(...) de la interfaz FeatureStore . Este método recibe como parámetros el tipo de fenómeno (FeatureType) y el nombre del atributo (que debe pertenecer al tipo de fenómeno especificado) sobre el que se desea crear un índice. Así mismo es necesario indicar un nombre para el índice, que servirá para identificarlo.
DataManager manager;
DataStoreParameters params;
FeatureStore store;
manager = DALLocator.getDataManager();
params = manager.createStoreParameters("Shape");
params.setAttribute("shpfileName","data/prueba.shp");
store = (FeatureStore) manager.createStore(params);
FeatureType fType = store.getDefaultFeatureType();
store.createIndex(fType, "municipio", "municipios_idx");
store.dispose();
La creación de un índice puede ser una operación costosa, por lo que el método se ha sobrecargado para admitir un observador, de manera que el proceso se pueda lanzar en segundo plano, y el observador sea notificado del progreso del mismo.
(...)
store.createIndex(fType, "municipio", "municipios_idx", this);
(...)
Obtener los índices de un almacén
Los índices de un almacén están almacenados en un FeatureIndexes . Se obtiene a partir del almacén y se puede iterar sobre él para acceder a todos los índices disponibles:
(...)
FeatureIndexes indexes = store.getIndexes();
Iterator it = indexes.iterator();
while (it.hasNext()) {
FeatureIndex index = (FeatureIndex) it.next();
System.out.println(index.getName());
}
(...)
Obtener un índice por nombre
El siguiente ejemplo muestra como obtener un índice del que se conoce el nombre:
(...)
FeatureIndex index = store.getIndexes().getFeatureIndex("municipio_idx");
System.out.println(index.getDataType());
System.out.println(index.getAttributeNames());
(...)
Como se observa en el ejemplo, el índice dispone de un método getAttributeNames que devuelve una List de String que contienen los nombres de los atributos indexados. En la actualidad sólo se soporta la creación de índices sobre un sólo atributo (en el método createIndex sólo se puede especificar un atributo), sin embargo el índice está preparado por si en el futuro se soporta la creación de índices multi-atributo.
Consultar un índice
Hay varias modalidades de consulta de un índice.
Coincidencia (match)
Este tipo de consulta devuelve los elementos del índice que intersectan con el conjunto definido por el objeto que se pasa como parámetro. Es decir, si se pasa un número entero y el índice es de tipo entero, entonces devolverá los elementos que sean iguales al número entero. Si por el contrario el parámetro representa un intervalo numérico entonces la consulta devolverá todos los elementos que pertenecen al intervalo. Si el índice es espacial y el parámetro es una geometría entonces la consulta devuelve los elementos que intersectan con ella. En el caso de datos espaciales, hay que tener en cuenta que los índices clasifican los extent de las geometrías con una precisión relativa a la granularidad (o profundidad) del índice por lo que se da el caso de que en el resultado hay geometrías que no intersectan realmente con la geometría parámetro, sino que lo que se devuelve es una aproximación que siempre es un superconjunto del resultado exacto.
El siguiente ejemplo hace una consulta espacial de tipo match sobre un índice:
(...)
GeometryManager gf = GeometryLocator.getGeometryManager();
Geometry geom = gf.createSurface(new GeneralPathX(
new Rectangle(1,1,100,100)),
Geometry.SUBTYPES.GEOM2D);
FeatureSet set = index.getMatchFeatureSet(geom.getEnvelope());
Iterator it = set.iterator();
while (it.hasNext()) {
Feature feat = (Feature) it.next();
System.out.println(feat.toString());
}
(...)
Rango
Este tipo de consulta recibe dos parámetros que delimitan un rango o intervalo. La consulta devuelve los elementos que pertenecen a este intervalo. Es un tipo de consulta pensado para atributos alfanuméricos o tipos de datos con una relación de orden, ya que en el caso de los datos espaciales no existe esta relación de orden y para filtrar por un rango se usa el tipo match y el rango viene representado por una geometría.
(...)
FeatureSet set = index.getRangeFeatureSet(value1, value2);
(...)
N elementos más cercanos
Este tipo de consulta devuelve los n elementos más cercanos al valor de referencia que se pasa como parámetro.
(...)
FeatureSet set = index.getNearestFeatureSet(count, value);
(...)
N elementos más cercanos con tolerancia
Este tipo de consulta funciona igual que la anterior pero se especifica una distancia máxima permitida del valor de referencia. Esta distancia máxima, o tolerancia, sirve para obtener N elementos como máximo, estando todos ellos a una distancia del valor de referencia menor o igual que la tolerancia indicada.
(...)
FeatureSet set = index.getNearestFeatureSet(count, value, tolerance);
(...)
El índice
El índice dispone de un conjunto de servicios para obtener información sobre él así como para manipular su contenido directamente. Son los siguientes:
Obtener su nombre
El nombre identifica al índice dentro de un almacén.
/** Index name */
public String getName();
Obtener los atributos asociados
La lista de nombres de los atributos indexados en el índice. En principio siempre tendrá un sólo elemento ya que de momento sólo se soporta la indexación por un único atributo. El servicio se incluye en previsión de que en el futuro se de soporte a índices compuestos.
/** Attribute names */
public List getAttributeNames();
Insertar un elemento
Permite insertar un fenómeno o un conjunto de fenómenos en el índice.
/**
* Inserts a Feature in the index.
* The Feature must contain a column that matches this index's column (name and data type)
* @param feat
*/
public void insert(Feature feat);
/**
* Inserts a FeatureSet into this index
* FeatureType is not checked so it will accept any FeatureType
* as long as exists a column with a valid name
*/
public void insert(FeatureSet data) throws DataException;
Eliminar un elemento
Permite eliminar un fenómeno o un conjunto de fenómenos del índice.
/**
* Deletes a Feature in the index.
* The Feature must contain a column that matches this index's column (name and data type)
* @param feat
*/
public void delete(Feature feat);
/**
* Deletes a FeatureSet from this index
* FeatureType is not checked so it will accept any FeatureType
* as long as exists a column with a valid name
*/
public void delete(FeatureSet data) throws FeatureIndexException;
Algunas recomendaciones sobre el uso de índices
El uso normal de los índices consiste únicamente en crearlos, porque es el propio almacén quien decide cuándo utilizarlos. Aun así es posible crear un índice y añadir o eliminar elementos al mismo. Esta posibilidad se ha dejado abierta para casos especiales en que se quiera tener control sobre el índice.
Se recomienda no crear índices locales para bases de datos que soporten índices. Es mucho mejor crear el índice en la base de datos (claro que normalmente hay que ser administrador de la misma) y así que sea la propia base de datos quien decida cuándo usarlo.
En cuanto a la creación de los índices, debido al coste de esta operación normalmente es recomendable ejecutar el proceso de indexación en segundo plano.
Introducción
Una transformación es un algoritmo que a partir de un fenómeno de un tipo produce otro fenómeno de otro tipo distinto, sin modificar el original. En otras palabras, copia una Feature cuyo FeatureType es A en otra Feature cuyo FeatureType es B, siendo la transformación T una función de correspondencia entre los FeatureType A y B: T(A)=B.
Este mecanismo se ha ideado para dar la posibilidad de crear vistas sobre almacenes de datos sin que sea necesario modificar los mismos, para que los datos se presenten al usuario de forma diferente a como están realmente estructurados.
DAL ofrece una interfaz para poder añadir transformaciones a un almacén. Esta interfaz se llama FeatureStoreTransform.
Documentación generada con maven: incluye JavaDoc, informes de test unitarios, validaciones de código, etc...
http://gvsig-desktop.forge.osor.eu/downloads/pub/projects/gvSIG-desktop/docs/reference/org.gvsig.fmap.dal/2.0.0/
A continuación se enumeran los jar que genera DAL. A la hora de indicar las dependencias de un proyecto que use DAL, hay que tener en cuenta que sólo habrá que incluir las dependencias marcados como necesarios para compilar. A la hora de hacer un build ejecutable, habrá que incluir también aquellas dependencias necesarios en tiempo de ejecución (normalmente correspondientes a las implementaciones) que son necesarios para que funcione gvSIG.
Los jar que se necesitan cargar en tiempo de ejecución disponen de una clase Library que permite cargarlos e inicializarlos durante el arranque de la aplicación (o en cualquier momento posterior), para más información sobre este mecanismo se puede consultar el patrón Locator.
| File |
Description |
Dependency Phase |
Consumer |
XML |
|---|
| org.gvsig.fmap.dal-[version].jar |
DAL api. If you are reading this, odds are you need this one |
Compile |
All |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal</artifactId>
<version>[version]</version>
</dependency>
|
| org.gvsig.fmap.dal-[version]-spi.jar |
DAL spi. If you want to implement a new provider, this one is for you |
Compile |
Data provider |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal</artifactId>
<version>[version]</version>
<classifier>spi</classifier>
</dependency>
|
| org.gvsig.fmap.dal-2.0-[version]-impl.jar |
DAL implementation. Nothing to see here, move along |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal</artifactId>
<version>[version]</version>
<classifier>impl</classifier>
</dependency>
|
| File |
Description |
Dependency Phase |
Consumer |
XML |
|---|
| org.gvsig.fmap.geometry-[version].jar |
gvSIG's geometry model |
Compile |
DAL |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.geometry</artifactId>
<version>[version]</version>
</dependency>
|
| org.gvsig.metadata-[version].jar |
gvSIG's, metadata library |
Compile |
DAL |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.metadata</artifactId>
<version>[version]</version>
</dependency>
|
| org.gvsig.tools-[version].jar |
gvSIG's base tools and patterns |
Compile |
DAL |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.tools</artifactId>
<version>[version]</version>
</dependency>
|
Los siguientes jares son implementaciones que vienen de serie para gvSIG-Desktop.
| File |
Description |
Dependency Phase |
Consumer |
XML |
|---|
| org.gvsig.fmap.dal.file-[version].jar |
File stores common API |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.file</artifactId>
<version>[version]</version>
</dependency>
|
| org.gvsig.fmap.dal.file-[version]-store.shp.jar |
SHP provider (extends of DBF provider) |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.file</artifactId>
<version>[version]</version>
<classifier>store.dbf</classifier>
</dependency>
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.file</artifactId>
<version>[version]</version>
<classifier>store.shp</classifier>
</dependency>
|
| org.gvsig.fmap.dal.file-[version]-store.dbf.jar |
DBF provider |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.file</artifactId>
<version>[version]</version>
<classifier>store.dbf</classifier>
</dependency>
|
| org.gvsig.fmap.dal.file-[version]-store.dxf.jar |
DXF provider |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.file</artifactId>
<version>[version]</version>
<classifier>store.dxf</classifier>
</dependency>
|
| org.gvsig.fmap.dal.file-[version]-store.dgn.jar |
DGN provider |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.file</artifactId>
<version>[version]</version>
<classifier>store.dgn</classifier>
</dependency>
|
| org.gvsig.fmap.dal.file-[version]-store.dxf.legend.jar |
DXF legend support |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.file</artifactId>
<version>[version]</version>
<classifier>store.dxf</classifier>
</dependency>
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.file</artifactId>
<version>[version]</version>
<classifier>store.dxf.legend</classifier>
</dependency>
|
| org.gvsig.fmap.dal.file-[version]-store.dgn.legend.jar |
DGN legend support |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.file</artifactId>
<version>[version]</version>
<classifier>store.dgn</classifier>
</dependency>
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.file</artifactId>
<version>[version]</version>
<classifier>store.dgn.legend</classifier>
</dependency>
|
| File |
Description |
Dependency Phase |
Consumer |
XML |
|---|
| org.gvsig.fmap.dal.db-[version].jar |
Database stores common API |
Runtime |
GeoDB (extGeoDB) |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.db</artifactId>
<version>[version]</version>
</dependency>
|
| org.gvsig.fmap.dal.db-[version].store.jdbc.jar |
Generic JDBC provider |
Runtime |
GeoDB (extGeoDB) |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.db</artifactId>
<version>[version]</version>
<classifier>store.jdbc</classifier>
</dependency>
|
| org.gvsig.fmap.dal.db-[version].store.mysql.jar |
MySQL JDBC provider (extends JDBC provider) |
Runtime |
GeoDB (extGeoDB) |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.db</artifactId>
<version>[version]</version>
<classifier>store.jdbc</classifier>
</dependency>
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.db</artifactId>
<version>[version]</version>
<classifier>store.mysql</classifier>
</dependency>
|
| org.gvsig.fmap.dal.db-[version].store.postgresql.jar |
PostgreSQL JDBC provider (with PostGis support) (extends JDBC provider) |
Runtime |
GeoDB (extGeoDB) |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.db</artifactId>
<version>[version]</version>
<classifier>store.jdbc</classifier>
</dependency>
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.db</artifactId>
<version>[version]</version>
<classifier>store.postgresql</classifier>
</dependency>
|
| File |
Description |
Dependency Phase |
Consumer |
XML |
|---|
| org.gvsig.fmap.dal.index.spatial-[version]-gt2.jar |
Geotools2 quadtree provider |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.index.spatial</artifactId>
<version>[version]</version>
<classifier>gt2</classifier>
</dependency>
|
| org.gvsig.fmap.dal.index.spatial-[version]-jsi.jar |
JSI rtree provider |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.index.spatial</artifactId>
<version>[version]</version>
<classifier>jsi</classifier>
</dependency>
|
| org.gvsig.fmap.dal.index.spatial-[version]-jts.jar |
JTS quadtree provider |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.index.spatial</artifactId>
<version>[version]</version>
<classifier>jsi</classifier>
</dependency>
|
| org.gvsig.fmap.dal.index.spatial-[version]-spatialindex.jar |
SPTLIB rtree provider |
Runtime |
gvSIG |
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.dal.index.spatial</artifactId>
<version>[version]</version>
<classifier>spatialindex</classifier>
</dependency>
|
| [version] | (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21) Versión de la librería, actualmente 2.0-SNAPSHOT, pero la versión final será 2.0.0 |
Cached time 11/21/13 17:32:03