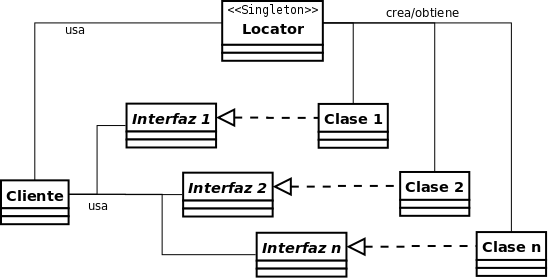
En el paquete org.gvsig.tools.exception se encuentra la base que los componentes de gvSIG utilizan para crear sus propias excepciones.
Las dos clases centrales, que definen los dos tipos básicos de excepción que se pueden crear, son BaseException y BaseRuntimeException. Ambas clases implementan la interfaz IBaseException y extienden respectivamente java.lang.Exception y java.lang.RuntimeException. Por tanto su manejo es similar al de cualquier excepción, y únicamente se requiere que las excepciones que extiendan de ellas incluyan determinados datos y métodos adicionales en sus implementaciones para que puedan incorporar el comportamiento deseado.
El uso de este modelo aporta algunas ventajas como la localización del mensaje, mejora de la trazabilidad, o el paso de información contextual al usuario y, en definitiva, la normalización del uso de excepciones en gvSIG.
Para crear un nuevo tipo de excepción basta con extender BaseException (o BaseRuntimeException). El siguiente ejemplo es una implementación completamente funcional de BaseException.
Ejemplo:
public class DriverException extends BaseException {
// Este código único se utiliza para identificar el tipo de excepción
private static final long serialVersionUID = -8985920349210629999L;
// Clave para localización
private static final String KEY = "Error_in_the_driver_%(driverName)s";
// Mensaje
private static final String MESSAGE = "Error in the driver %(driverName)s";
// Miembro/s que contiene/n información contextual propia de cada clase de excepción.
private String driverName;
// Constructor con información contextual.
public DriverException(String driverName) {
super(MESSAGE, KEY, serialVersionUID);
this.driverName = driverName;
}
// Constructor con una causa origen, se usa cuando lanzamos una excepción después de capturar otra
public DriverException(String driverName, Throwable cause) {
super(MESSAGE, cause, KEY, serialVersionUID);
this.driverName = driverName;
}
// Este es el constructor completo que requiere BaseException.
public DriverException(String driverName, String message, Throwable cause,
String key, long code) {
super(message, cause, key, code);
this.driverName = driverName;
}
// Implementación del método abstracto que devuelve un Map con los valores contextuales a sustituir en el mensaje
protected Map values() {
HashMap values = new HashMap();
values.put("driverName",this.driverName);
return values;
}
}
Como regla general, si el código cliente puede tratar la excepción o recuperarse de ella de alguna forma razonable, entonces dicha excepción debe extender BaseException. Si, por el contrario, el cliente no puede hacer nada con la excepción, entonces se puede extender BaseRuntimeException, de manera que no hará falta declararla en el API ni capturarla directamente en el código cliente.
Para una explicación más detallada acerca de esta recomendación se puede visitar: http://java.sun.com/docs/books/tutorial/essential/exceptions/runtime.html
Clonación de objetos
En algunas ocasiones tenemos la necesidad de poder realizar copias de ciertos objetos, o como se suele decir también, de poder clonarlos. Supongamos que tenemos la siguiente una jerarquía de objetos, a modo de ejemplo:
El código de estas clases sería algo como:
public class Dependency {
private int value;
// followed by a getter and setter for the value attribute
...
}
public class Parent {
private String text;
private Date creation;
// followed by getters and setters for the text and creation attributes
...
}
public class Child extends Parent {
private float price;
private Dependency dependency;
// followed by getters and setters for the price and dependencty attributes
...
}
En este ejemplo, podríamos tener una instancia de la clase Child, y el objetivo sería obtener una copia.
Existen diversas formas habituales de implementarlo, entre las que se incluyen: constructor de copia, factoría, etc. Una de las más habituales es que el propio objeto provea de un método que nos devuelva una copia del mismo.
De hecho, en Java suele emplearse el método clone() y el interfaz Cloneable. El interfaz java.lang.Cloneable es un interfaz vacío que sirve para indicar al método clone() de java.lang.Object que se puede hacer una copia de un objeto a partir de sus campos.
Sin embargo, como se indica en el javadoc del propio interfaz java.lang.Cloneable, por convención, clases que implementen dicho interfaz, deberían sobreescribir el método clone(), que es protected en Object, por otro que sea public.
Para dejar más claro este esquema, se ha definido un interfaz org.gvsig.tools.lang.Cloneable que extiende a java.lang.Cloneable y define, a su vez, el método clone() como público.
Así, cuando queramos que un objeto soporte la creación de copias de sí mismo, implementaremos el interfaz org.gvsig.tools.lang.Cloneable, e implementaremos el método clone().
¿Cómo implementamos el método clone()? Por lo general bastará con llamar al clone() de la clase Object.
Sobre el ejemplo anterior, quedaría así:
public class Dependency implements org.gvsig.tools.lang.Cloneable {
private int value;
// followed by a getter and setter for the value attribute
...
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class Parent implements org.gvsig.tools.lang.Cloneable {
private String text;
private Date creation;
// followed by getters and setters for the text and creation attributes
...
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class Child extends Parent implements org.gvsig.tools.lang.Cloneable {
private float price;
private Dependency dependency;
// followed by getters and setters for the price and dependencty attributes
...
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
Con esto ya tendría una implementación de clonación básica. Desde código, bastaría con hacer lo siguiente para obtener un clon de un objeto Child:
Child child = new Child();
...
Child childClone = (Child)child.clone();
Sin embargo, tenemos algunos problemas debido al funcionamiento de la clonación base y cómo funciona el modelo de ejemplo:
- El valor del atributo Parent.creation no queremos que sea el mismo que el de la clase clonada, ya que queremos que tenga la fecha de creación del objeto.
Para resolverlo bastará con modificar la implementación del método Parent.clone() para que asigne la fecha actual en el momento de realizar la clonación:
public class Parent implements org.gvsig.tools.lang.Cloneable {
private String text;
private Date creation;
// followed by getters and setters for the text and creation attributes
...
public Object clone() throws CloneNotSupportedException {
Parent clone = (Parent)super.clone();
clone.creation = new Date();
return clone;
}
}
La lógica del método clone() de la clase Object habrá copiado todos los valores desde nuestra instancia a la clonada por asignación (shallow copy), es decir:
- Si se trata de un tipo básico, se copia su valor.
- Si se trata de un objeto, se copia su referencia.
Con esto, la referencia la objeto de tipo Dependency será la misma en ambos objetos, el original y el clonado. Es decir, los dos apuntarán a la misma instancia de Dependency:
Dado que dependency es un objeto mutable y podemos modificar su estado, no podemos compartir la misma instancia entre el objeto original y el clonado, ya que modificaciones desde uno afectarían al otro.
Deberemos crear una instancia propia de Dependency para el objeto clonado, que sea una copia de la del objeto original:
A nivel de implementación, la clase Child quedaría como sigue aprovechando que Dependency es, a su vez, Cloneable:
public class Child extends Parent implements org.gvsig.tools.lang.Cloneable {
private float price;
private Dependency dependency;
// followed by getters and setters for the price and dependencty attributes
...
public Object clone() throws CloneNotSupportedException {
Child clone = (Child) super.clone();
clone.dependency = (Dependency)dependency.clone();
return clone;
}
}
Pasará lo mismo con otros atributos de tipo objeto, como es el caso del atributo Parent.text. Sin embargo, el atributo text es de tipo String, la cuál tiene la particularidad de ser inmutable, por lo que podemos compartir la referencia sin problemas.
Resumiendo, a la hora de implementar la clonación de una clase, seguiremos los siguientes pasos:
- Implementaremos el interfaz org.gvsig.tools.lang.Cloneable.
- Implementaremos el método clone().
- A la hora de crear el nuevo objeto copia a devolver, no usaremos new, sino que invocaremos al clone() del super:
- Adaptaremos la copia obtenida en el paso anterior, según la lógica de nuestra clase, fijándonos sólo en los atributos que define nuestra clase, y no en los que puedan definir clases padre. Tendremos distintos casos de atributos, según su tipo:
- Tipo básico: ya tendremos el valor copiado de nuestro atributo al del objeto clonado. Sólo tendremos que hacer algo si no queremos que ese valor se copie o tenga un valor distinto.
- Tipo objeto inmutable: es decir, aquellos que una vez contruidos, ya no puede cambiarse su estado, como por ejemplo la clase String, Integer, etc. En este caso, no será necesario hacer nada ya que, aunque tendremos en los dos objetos (el original y el clonado) una referencia a un mismo objeto, éste no puede cambiar su estado, por lo que no nos afectará lo que hagamos en un objeto sobre el otro para este atributo.
- Tipo objeto mutable: en este caso, a no ser que nos interese así, porque se trate de un dato común, o por ejemplo una referencia a un servicio, deberemos clonar el valor del atributo.
Se puede ver más información sobre clonación en el siguiente tip del Java Developer Connection sm(JDC) Tech Tips, March 6, 2001
En gvSIG tenemos una serie de proyectos que actúan como librerías para aportar una funcionalidad determinada. Por lo general, muchas de esas librerías suelen requerir algún tipo de inicialización: definir valores por defecto, cargar un archivo, registrar clases, etc.
Anteriormente, dicha inicialización no estaba definida, por lo que en cada librería nos podíamos encontrar con un mecanismo distinto: código estático, singleton, etc.
Con el fin de normalizar este proceso se ha definido un API para la inicialización y configuración de librerías. En realidad, para cualquier tipo de proyecto, como por ejemplo una extensión de gvSIG.
El API es muy sencillo, consiste en un interfaz Library que define dos métodos muy parecidos a los del interfaz IExtension de Andami, y una clase abstracta AbstractLibrary para facilitar el desarrollo:
La idea es que primero se llamará a todas los initialize de los Library de la aplicación, y a continuación todos los postInitialize, al igual que se hace con las extensiones de Andami. De hecho, dentro de gvSIG, los initialize de las Library se invocará justo antes que los initialize de las extensiones, y lo mismo con el método postInitialize.
Además se ha desarrollado una clase AbstractLibrary para facilitar el desarrollo de estas clases, incluyendo un control de ejecución para que una Library se inicialice sólo una vez dentro de una misma aplicación, aunque se invoque varias veces a sus métodos post/initialize.
Uno de los casos de uso más habituales será el registro de implementaciones en los Locator. Cada librería que emplee el mecanismo del Locator deberá implementar un Library para su API, y otro para su implementación (ver ejemplo en org.gvsig.tools.locator).
- Librería de API:
- El Library implementará el método doPostInitialize(), dentro del cuál se hará la comprobación de que alguna implementación haya sido registrada.
- Librerías de implementación:
- El Library, en su método doInitialize(), se encargará de registrar las implementaciones que aporta la librería a través del locator de su correspondiente librería de API.
En ambos casos, los métodos del Library también podrán ser usados para realizar otros tipos de inicializaciones, como definir variables de librería, cargar configuraciones, obtener recursos, etc.
Se ha desarrollado un mecanismo que facilite la inicialización automática de las librerías de una aplicación, como por ejemplo gvSIG o cualquier test unitario.
Para ello se ha definido un interfaz LibrariesInitializer y una implementación basada en el mecanismo de registro de servicios disponible en el JDK. Dicho mecanismo varía según el JDK empleado, pasando de una clase interna (sun.misc.Service), a formar parte del API público a partir de Java 1.6 (java.util.ServiceLoader).
Podemos encontrar más información en la especificación de los archivos JAR, bien de la versión 1.4.2, 1.5, o 1.6.
A partir de la versión 1.6 de Java disponemos también del API de la clase ServiceLoader
La implementación realizada se basa en el uso de reflection para buscar una implementación disponible, independientemente de la versión de JDK empleado, por lo que podremos usarla en cualquier versión de Java >= 1.3.
El uso de esta inicialización automática, una vez los jars de las librerías contienen la información necesaria y se encuentran en el classpath de ejecución, consiste en instanciar e invocar al LibrariesInitializer.
Este contiene los siguientes métodos:
- initialize: invoca a todos los initialize de las librerías encontradas.
- postInitialize: invoca a todos los postInitialize de las librerías encontradas.
- fullInitialize: método de utilidad que llama primero a todos los initialize, y a continuación a todos los postInitialize.
En gvSIG, andami se encargará de llamar al LibrariesInitializer correspondiente, creando uno por cada plugin cargado. Entonces llamará al initialize del LibrariesInitializer antes de llamar al de las extensiones de cada plugin. A continuación, hará lo mismo con los postInitialize.
En los tests unitarios, por ejemplo, se empleará el método fullInitialize directamente desde el método setUp. Ej:
protected void setUp() throws Exception {
super.setUp();
new DefaultLibrariesInitializer().fullInitialize();
....
}
Para facilitar el desarrollo de tests unitarios, con la inicialización automática de librerías, se ha creado una clase AutoLibsTestCase que se encargará de realizar la inicialización anterior. En este caso, la inicialización de nuestros tests la haremos a través del método doSetUp.
Para que funcione la inicialización automática de librerías, con la implementación que se ha desarrollado, en cada proyecto deberemos registrar las implementaciones de Library que se aportan, para que el inicializador sea capaz de encontrarlas.
Dicho mecanismo, tal y como se explica en el punto anterior, se basa en el registro de servicios de Java. En nuestro caso concretamente consistirá en un archivo de texto llamado org.gvsig.tools.library.Library dentro de la carpeta META-INF/services, cuyo contenido será el nombre o nombres de las clases que implementan Library en nuestro proyecto, e incluirlo en el jar a generar o en el classpath de ejecución.
A continuación se detallan los pasos a realizar, según la estructura de proyecto que tengamos, o si nuestro proyecto genera un único jar o varios:
Crearemos los directorios donde incluir el archivo de registro de nuestras implementaciones:
Si nuestro proyecto genera un único jar:
Si tenemos estructura de maven, crearemos el directorio:
src/main/resources/META-INF/services
Si NO tenemos estructura de maven, crearemos el directorio:
resources/META-INF/services
Si nuestro proyecto genera varios jars:
Crearemos un directorio por cada jar que se genere e incluya algún Library
Si tenemos estructura de maven, por ejemplo, si nuestro proyecto genera un jar con el API y otro con la implementación, crearemos los directorios:
src/main/resources-api/META-INF/services
src/main/resources-impl/META-INF/services
Si NO tenemos estructura de maven, siguiendo el ejemplo anterior los directorios serían:
resources/api/META-INF/services
resources/impl/META-INF/services
Incluiremos un archivo org.gvsig.tools.library.Library en cada uno de los directorios creados en el paso anterior.
Editaremos cada uno de los archivos anteriores y añadiremos las clases que implementan Library según corresponda al jar en el que van a ir includas.
Configuraremos el pom.xml para que se incluyan los archivos anteriores en los archivos .jar generados y en el classpath de ejecución de los tests unitarios:
Si nuestro proyecto genera un único jar:
Si tenemos estructura de maven, no es necesario añadir nada, ya se incluye por defecto el directorio src/main/resources.
Si NO tenemos estructura de maven, deberemos incluir el directorio resources añadiendo el siguiente código dentro del apartado <build></build>:
<resources>
<resource>
<directory>${basedir}/resources</directory>
</resource>
</resources>
Si nuestro proyecto genera varios jars:
Deberemos emplear el plugin maven-antrun-plugin para incluir cada archivo en su correspondiente archivo jar generado. Además incluiremos los directorios resources en el classpath de ejecución de los tests unitarios. Siguiendo con el ejemplo de un proyecto que genera un jar de API y otro de implementación, haremos lo siguiente:
Si tenemos estructura de maven, incluiremos dentro del apartado <build><plugins></plugins></build>:
<plugin>
<artifactId>maven-antrun-plugin</artifactId>
<executions>
<execution>
<id>services</id>
<phase>package</phase>
<goals>
<goal>run</goal>
</goals>
<configuration>
<tasks>
<jar destfile="${project.build.directory}/${project.build.finalName}.jar"
update="true">
<fileset dir="${basedir}/src/main/resources-api/" />
</jar>
<jar destfile="${project.build.directory}/${project.build.finalName}-impl.jar"
update="true">
<fileset dir="${basedir}/src/main/resources-impl" />
</jar>
</tasks>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<additionalClasspathElements>
<additionalClasspathElement>${basedir}/src/main/resources-api</additionalClasspathElement>
<additionalClasspathElement>${basedir}/src/main/resources-impl</additionalClasspathElement>
</additionalClasspathElements>
</configuration>
</plugin>
Si NO tenemos estructura de maven, será lo mismo, cambiando la ubicación de las carpetas a incluir:
<plugin>
<artifactId>maven-antrun-plugin</artifactId>
<executions>
<execution>
<id>services</id>
<phase>package</phase>
<goals>
<goal>run</goal>
</goals>
<configuration>
<tasks>
<jar destfile="${project.build.directory}/${project.build.finalName}.jar"
update="true">
<fileset dir="${basedir}/resources/api" />
</jar>
<jar destfile="${project.build.directory}/${project.build.finalName}-impl.jar"
update="true">
<fileset dir="${basedir}/resources/impl" />
</jar>
</tasks>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<additionalClasspathElements>
<additionalClasspathElement>${basedir}/resources/api</additionalClasspathElement>
<additionalClasspathElement>${basedir}/resources/impl</additionalClasspathElement>
</additionalClasspathElements>
</configuration>
</plugin>
Finalmente configuraremos eclipse para que tenga en cuenta los archivos de registro de implementaciones de Library en el classpath de ejecución de nuestro proyecto (por ejemplo, para poder emplear la inicialización automática de librerías desde los tests unitarios):
Si nuestro proyecto genera un único jar: al generar el proyecto de eclipse desde maven, ya se configurará correctamente, incluyendo la carpeta resources en el classpath del proyecto.
Si nuestro proyecto genera varios jars: por ahora no hemos conseguido que en este caso se configure correctamente el proyecto de eclipse al generarlo desde maven, ya que no se incluyen las carpetas resources- en el classpath. Por lo tanto tendremos que incluirlas a mano.
Para ello, una vez generado y cargado el proyecto de eclipse, accederemos a las propiedades de proyecto, y dentro de estas seleccionaremos el apartado Java Build Path. Seleccionaremos la pestaña libraries y pulsaremos el botón Add Class Folder, seleccionando cada una de las carpetas resources de nuestro proyecto.
En los tests unitarios, para emplear la inicialización automática bastará con:
Incluir en el classpath de ejecución los jars necesarios, en los que se incluyan las librerías que necesitemos. Básicamente habrá que incluir como dependencias las librerías necesarias dentro del archivo pom.xml de nuestro proyecto, para maven, y regenerar el proyecto de eclipse.
En algunos casos tendremos dependencia de compilación en nuestro proyecto con una librería de API determinada, por ejemplo la de geometrías (libFmap_geom), por lo cuál la tendremos que tener como una dependencia más en el archivo pom.xml de maven. Además, para poner en funcionamiento nuestros tests, necesitaremos también alguna implementación. En dichos casos, incluiremos la dependencia también en el archivo pom.xml, pero indicando que sólo es para la ejecución de los tests, mediante el atributo scope. Ej:
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.geometry</artifactId>
<version>2.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.fmap.geometry</artifactId>
<version>2.0-SNAPSHOT</version>
<classifier>impl</classifier>
<scope>test</scope>
</dependency>
Hacer que nuestra clase de test extienda la clase:
org.gvsig.tools.junit.AbstractLibraryAutoInitTestCase
Dicha clase se encarga de realizar la inicialización de todas las librerías que se encuentran en el classpath de ejecución del test de forma automática.
Al extender esta clase ya no podremos emplear el método setUp para inicializar nuestro test, sino que tendremos que pasar a emplear el método doSetUp.
Además necesitaremos incluir el jar de tests de libTools como dependencia en nuestro proyecto, incluyendo lo siguiente:
<dependency>
<groupId>org.gvsig</groupId>
<artifactId>org.gvsig.tools</artifactId>
<version>2.0-SNAPSHOT</version>
<classifier>tests</classifier>
<scope>test</scope>
</dependency>
Las excepciones del Library son de tipo RuntimeException por lo que, aunque declaradas en su API, no obligan a ser capturadas mediante un try ... catch. A nivel de aplicación, sí que habrá que hacer un tratamiento de estas excepciones, para mostrar al usuario algún tipo de información sobre el error producido.
No se han definido excepciones normales, ya que son errores graves y no se puedan tratar desde código. Así no obligamos a capturarlas en cada lugar donde se use un Library, y se pueden tratar en un nivel superior.
Una parte en la que se ha hecho mucho hincapié en lo que es la 2.0
ha sido la separación entre API e implementación. Para facilitar y
estandarizar la forma de trabajar con esto, en org.gvsig.tools hay
dos paquetes que presentan utilidades relacionadas con ello.
- org.gvsig.tools.library, que aporta los mecanismos de
carga y descubrimiento de librerías en tiempo de ejecución.
- org.gvsig.tools.service, que aporta el entorno para realizar
la separación entre API/implementación/SPI/proveedores.
Este documento va a tratar sobre este último punto, intentando dar
una visión ya no de qué es lo que aporta, si no, en la medida de lo
posible, de por qué se ha decidido hacer de esta forma.
Hay que tener en cuenta que este marco se ha ido confeccionando a lo
largo del desarrollo realizado entorno a gvSIG 2.0, con lo que
los desarrollos de la 2.0 que se empezaron en sus primeros momentos,
aunque ya aparecen los conceptos que aquí se formalizan, aún no usan
el entorno que se va a describir.
Cuando vamos a realizar un desarrollo podemos encontrarnos con
varios escenarios:
- API/implementación. Vamos a generar una librería con la
lógica de nuestro desarrollo en la que vamos a separar el API
de su implementación.
- API/SPI/implementaciones múltiples de servicios (MSI). En este
caso vamos a tener la opción de tener diferentes implementaciones
de los servicios de nuestro API.
- API/SPI/implementación basada en proveedores (PBI). En este escenario la implementación
del API puede llegar a tener varios proveedores de servicios.
Los conceptos que se abordan aquí van ligados a la
estructura de un proyecto para gvSIG 2.0, y conviene tener en
mente la estructura de proyecto multimódulo propuesta para los
desarrollos de gvSIG 2.0.
La primera aproximación que vamos a hacer consiste en que nuestra
librería presenta una serie de servicios que ofrece a través
de un API, pudiendo tener una o varias implementaciónes para estos.
Para ello crearemos un proyecto en el que dejaremos caer los interfaces
que definen nuestro API y otro con la implementación para ellos. Normalmente
tendremos un interface manager que actúa a modo de factoría de los distintos
servicios que vamos a ofrecer y un interface por cada servicio que vayamos
a ofrecer.
Para ir ilustrando esto partiremos de un proyecto ficticio llamado FortuneCookie.
Tendremos dos proyectos:
- org.gvsig.fortunecookie.lib.api, con los interfaces que exponga nuestro
desarrollo.
- org.gvsig.fortunecookie.lib.impl, con las clases que provean de una
implementación por defecto para ellos.
Para definir el API crearemos básicamente dos interfaces, FortuneCookieManager
y FortuneCookieService.
FortuneCookieManager. Presenta un interface simple que se encarga de
instanciar un FortuneCookieService, y devolvérselo al cliente para que
trabaje con él.
Además de hacer de factoría, podría llevar la gestión de configuración general
de la librería.
FortuneCookieService. Define el API a usar para obtener un fortune cookie.
En nuestro ejemplo sólo vamos a tener un método: getMessage.
public interface FortuneCookieManager {
public FortuneCookieService getFortuneCookieService();
}
public interface FortuneCookieService {
public String getMessage();
}
Además de esto deberemos tener en cuenta el manejo de excepciones, así como
la creación del locator y library correspondiente para poder
acceder a estos servicios. Así tendremos:
- FortuneCookieLibrary. Extenderá la clase AbtractLibrary e
implementará los métodos "do*", normalmente dejándolos vacíos.
En la parte del API el library en general no realiza
ninguna operación.
- FortuneCookieLocator. Derivará de la clase AbstractLocator
e implementará lo necesario para poder recuperar una implementación
del FortuneCookieManager que esté disponible. Consulte la documentación
sobre el locator para más informacion sobre él.
La compilación de este proyecto nos generará una librería
org.gvsig.fortunecookie.lib.api.jar (falta el número de versión), que contendrá
la definición del API de nuestro desarrollo. Esta librería es la que necesitarán
nuestros proyectos en tiempo de compilación para acceder a nuestro
servicio. Recordad que trabajando con maven podemos especificar
dependencias indicando si son de tiempo de compilación, ejecución o testing.
Por otro lado tendremos el proyecto en el que residirá la implementación de
nuestro API. Siguiendo las recomendaciones en el nombrado de clases para
gvSIG 2.0, nos encontraremos con las clases:
- DefaultFortuneCookieManager. Esta clase implementará el interface
FortuneCookieManager, encargándose de la creación de las instancias
de nuestro FortuneCookieService.
- DefaultFortuneCookieService. Esta es la clase que contendrá la lógica
usada para conseguir los mensajes de nuestras fortune cookie.
public class DefaultFortuneCookieManager implements FortuneCookieManager {
public FortuneCookieService getFortuneCookieService() {
return new DefaultFortuneCookieService(this);
}
}
public class DefaultFortuneCookieService implements FortuneCookieService {
private DefaultFortuneCookieManager manager;
private String msg;
public DefaultFortuneCookieService(DefaultFortuneCookieManager manager) {
this.manager = manager;
this.msg = null;
}
public String getMessage() {
if( this.msg != null ) {
return this.msg;
}
...
//Here we would generate the message
...
return this.msg;
}
}
Y al igual que en el proyecto del API aquí tendríamos el library
correspondiente, que se encargaría de registrar la implementación
de nuestro manager para que pudiese ser recuperada por el locator
del API.
Hay que tener en cuenta que el manager actúa a modo de singleton,
de forma que una vez recuperada una instancia de él siempre nos
devolverá la misma instancia, siendo global a la aplicación que
consuma nuestro servicio. Esto, en el ejemplo de nuestras fortune cookies,
no tiene especial relevancia, pero en otros escenarios más complejos
puede llegar a tenerla.
La compilación de este proyecto nos generará una librería
org.gvsig.fortunecookie.lib.impl.jar con una implementación de nuestro
API. Conviene recordar que las dependencias entre estos dos
proyectos, API e implementación, son, que la implementación depende del
API pero nunca al revés.
Como conclusión conviene observar que las utilidades de org.gvsig.tools.service
no nos han ofrecido ningún mecanismo especial para llevar a cabo nuestro
proyecto. Al final han sido una serie de prácticas recomendadas lo único
que hemos aplicado. Esto en gran parte debido a que el escenario de API
mas una implementación en bloque de la lógica de ese API no requiere
de más infraestructura.
Note
TODO Esta pendiente redactar esta seccion
El siguiente diagrama nos muestra las relaciones de estos interfaces y clases
con nuestro escenario de fortune cookie.
Cuando nos encontramos con un escenario en el que para dar el servicio
que ofrece nuestra API, además de la propia lógica de nuestra implementación
tenemos que servirnos de proveedores para algún servicio que puede usar
nuestra librería, la cosa se complica.
Básicamente se trata del escenario en el que la implementación de
nuestro servicio requiere a su vez de una serie de proveedores de otros
servicios.
Vamos a seguir con el ejemplo de nuestras fortune cookies, aunque
aquí está más cogido por los pelos, ya que nuestro servicio no ofrece
mucho más valor añadido del que puedan ofrecer los proveedores que use
el mismo.
Al igual que en el caso simple de separación entre API e implementación
tendremos, un manager y un servicio, pero ahora además necesitaremos algunas
cosas más. Entrarán en juego
- un proveedor de los servicios que precise nuestra
implementación.
- una factoría para instanciar a esos proveedores.
- Tendremos también un manager que gestione a los
proveedores
- Y alguien encargado de extender el API con las acciones
que puedan ser necesitadas por un proveedor.
Y además tendremos que separar la parte de la implementación que
usa y gestiona a los proveedores del API que ofrezcamos a estos
para interactuar con nuestra librería, el SPI.
En este proyecto nos encontraremos con la parte de API de nuestra librería.
Tendremos:
- FortuneCookieManager
- FortuneCookieService.
- FortuneCookieLocator
- FortuneCookieLibrary
Esta parte básicamente sigue presentando un aspecto similar
al del ejemplo simple. Si lo pensamos tiene su lógica, ya que
se identifica con los servicios que ofrece nuestra librería y
estos deberían ser independientes de como estén implementados.
El SPI constituye el contrato que ofrece nuestra librería hacia
sus proveedores de servicios, así que como tal es similar a la
definición del API. Estará constituido principalmente por una
serie de interfaces y ocAsíonalmente alguna clase abstract que
facilite la implementación de un proveedor.
Nos encontraremos con:
FortuneCookieProvider. Se tratará del interface que deben
cumplir los proveedores de servicios que usará nuestra librería.
FortuneCookieProviderServices. Representa a los servicios
adicionales que debe proveer nuestro FortuneCookieService de cara
a un proveedor. Hay que tener en cuenta que los proveedores no
deben tener acceso a la implementación de la librería. Al igual
que un cliente de ésta sólo tendrá acceso a su API un proveedor
sólo tendrá acceso a su SPI, así que, si debemos proveer de
algún servicio a nuestro proveedor deberemos exponerlo a través
de esta interface.
FortuneCookieProviderFactory. Por cada tipo de proveedor que
tenga nuestra librería necesitaremos una factoría que nos proporcione
instancias de ese tipo de proveedores, así que parece razonable
que exista un interface que nos proporcione el contrato que
deban cumplir esas factorías.
Normalmente, no deberemos preocuparnos por este interface, ya que
la librería provee del interface ProviderFactory que nos suministrará
todos los servicios que precisemos relacionados con la factoría de proveedores.
FortuneCookieProviderManager. Necesitaremos mantener un
registro de las factorías de proveedores con las que vamos a
trabajar, así que crearemos un manager específico para gestionar
todo lo que tenga que ver con nuestros proveedores.
Ahora veamos que nos quedará en la parte de implementación:
DefaultFortuneCookieManager, similar al que ya teníamos en
nuestro escenario simple sin proveedores.
La principal diferencia con respecto al del escenario anterior
estará en que este necesita gestionar proveedores, así que
simplemente tendrá una referencia al FortuneCookieProviderManager
y algún método para recuperarla.
DefaultFortuneCookieProviderManager, que tendrá la implementación
por defecto del manager encargado de la gestión de nuestros proveedores
de servicios.
DefaultFortuneCookieService, que al igual que en el escenario simple
presentará la implementación del servicio que ofrece nuestra librería
a sus clientes. La principal diferencia respecto la anterior versión
estará en que para alguna de sus funciones, en lugar de implementarlas
directamente, delegará en un proveedor que le será suministrado
en el momento de su contrucción.
DefaultFortuneCookieProviderServices. Esta clase implementará los
servicios que nuestra librería expone hacia los proveedores de esta.
DefaultFortuneCookieLibrary, que al igual que en nuestro escenario
simple, se encargará de registrar esta implementación.
Por ultimo deberemos disponer de alguna implementación de un proveedor
de servicios de nuestra librería. En nuestro ejemplo, nos encontraremos:
- FortuneCookieWebProvider, que nos brindará los servicios de
obtención de nuestras fortune cookies obteniéndolas a través de un
servicio web.
- FortuneCookieWebProviderFactory, que será la implementación de
la factoría para la construcción de FortuneCookieWebProvider.
- FortuneCookieWebLibrary, que se encargará de registrar este
proveedor como un proveedor de servicios de nuestra librería.
Y por cada proveedor de servicios de nuestra librería aparecería
su implementación, su factory y su library, habiendo tantos
como proveedores de servicios distintos tengamos.
Así como en el caso del escenario simple, en el que solo tenemos un API y
su implementación la librería org.gvsig.tools no nos ofrecía utilidades
para su implementación debido a la simplicidad de este, en el caso de
que hayan proveedores de servicios de nuestra librería sí que nos ofrece
todo un entorno de trabajo para facilitarnos la tarea. Encontraremos
interfaces de los que extender en nuestra definición del API y SPI, y
clases abstractas que extender a la hora de contruir nuestra implementación
o nuestros proveedores, librándonos de las faenas de registro de los proveedores,
o de recuperar instancias de estos cuando los precisemos.
El siguiente diagrama nos muestra las relaciones de estos interfaces y clases
con nuestro escenario de fortune cookie.
En el esquema podemos observar ocho bloques bien diferenciados. Cuatro con los
interfaces y clases que ofrece org.gvsig.tools.service y otros cuatro que
deberá aportar nuestro desarrollo.
Los siguientes bloques los aporta org.gvsig.tools.service para facilitarnos
nuestro desarrollo y homogeneizar la implementación de este escenario:
- General API. Este bloque contiene los interfaces que nos ayudaran a
definir el API de nuestro desarrollo.
- General SPI. Aquí encontraremos los interfaces que nos facilitarán
el definir el SPI de nuestro producto.
- General API impl. Nos aporta una serie de clases abtractas de cara
a ser extendidas por la implementación de nuestra librería para
definir el API de esta.
- General SPI impl. Nos aporta una serie de clases abtractas de cara
a ser extendidas por la implementación de nuestra librería para
definir el SPI de esta.
Los otros cuatro bloques representan código que deberemos aportar en nuestra
librería. Estos serían:
- Domain specific API. En nuestro ejemplo sería
org.gvsig.fortunecookie.lib.api, y estaría formado por
los interfaces que definen el API de nuestra librería.
- Domain specific SPI. Aqui tendríamos la parte de definición
del SPI de nuestra librería. Estaría relacionado con el código
que encontraríamos en org.gvsig.fortunecookie.lib.api.
- Default implementación. Estaría formado por la implementación
de la lógica de nuestra librería.
- Concrete provider. Representa las clases que habría que
crear para disponer de un proveedor de datos para nuestra librería.
Entes de pasar a resumir los pasos que deberíamos dar para implementar
este tipo de escenario, comentaremos algo sobre la construcción de los
proveedores de servicios de nuestra librería.
Normalmente cada proveedor de servicios, aunque exponga un contrato común
a todos los proveedores de servicios hacia nuestra implementación, precisará
de una serie de parámetros diferentes para cada proveedor. Así, siguiendo con nuestro ejemplo, FortuneCookieWebProvider podría precisar de
la url de acceso al servicio web que nos proporcione los distintos mensajes,
pero podríamos disponer de otro proveedor, FortuneCookieDBProvider, que fuese
a buscar los mensajes a una BBDD, y entre sus parámetros precise una cadena
de conexión a la BBDD y un nombre de tabla de la que extraer los mensajes.
Y también podríamos disponer de FortuneCookieXMLFileProvider que recibiese
la ruta de un fichero XML.
Básicamente cada proveedor, ofrece un interface
común a nuestra aplicación, getMessage, pero precisa de unos parámetros
particulares para su creación.
Para uniformizar esto, la factoría del proveedor dispondrá un método que nos
devuelva un DynObject en el que depositar estos parámetros y que luego
utilizará el proveedor para poder trabajar.
Así un cliente de nuestra librería, para empezar a trabajar con un servicio de los
que ofrezca nuestro desarrollo, lo primero que tendrá que hacer es pedirle al
FortuneCookieManager que le dé un DynObject en el que almacenar los
parámetros del proveedor con el que vayamos a trabajar a traves del método
getProviderParameters(String providerName), para luego invocar a getFortuneCookieService
pasándole esos parámetros.
A través de este apartado se irán enumerando las directrices a seguir para poder generar nuestro proyecto y comenzar el desarrollo.
En un primer paso, deberemos preparar el sistema de directorios para poder albergar el proyecto. Para ello, realizaremos las siguientes tareas:
Crear el directorio raíz que contendrá el proyecto. Siguiendo con la nomenclatura descrita hasta el momento, el proyecto deberá comenzar con org.gvsig. más el nombre del proyecto (en nuestro caso org.gvsig.fortunecookies).
Crear el subdirectorio LIB dentro del directorio raíz (en nuestro caso sería org.gvsig.fortunecookies.lib)
Creamos y editamos el fichero POM en org.gvsig.fortunecookies
- Añadimos el módulo LIB como hijo del directorio raíz, para que lo incluya en el proyecto
Creamos el proyecto API (org.gvsig.fortunecookies.lib.api) en org.gvsig.fortunecookies/org.gvsig.fortunecookies.lib
- Abrimos la consola y nos dirigimos al directorio en el que queremos generar el proyecto (org.gvsig.fortunecookies/org.gvsig.fortunecookies.lib).
- Ejecutamos la orden de Maven ->
mvn archetype:generate \
-DarchetypeGroupId=org.gvsig \
-DarchetypeArtifactId=org.gvsig.library-archetype \
-DgroupId=org.gvsig \
-DartifactId=org.gvsig.fortunecookies.lib.api \
-Dversion=1.0 \
-Dpackage=org.gvsig.fortunecookies.lib.api
- Indicamos como arquetipo la opción 17 y confirmamos la opción indicando Yes (valores por defecto)
Creamos y editamos el fichero POM en org.gvsig.fortunecookies/org.gvsig.fortunecookies.lib
- Especificamos el módulo padre
- Añadimos el módulo API como hijo del directorio org.gvsig.fortunecookies.lib, para que lo incluya en el proyecto
Editamos el fichero POM de org.gvsig.fortunecookies/org.gvsig.fortunecookies.lib/org.gvsig.fortunecookies.lib.api
- Especificamos que el módulo padre es org.gvsig.fortunecookies.lib
A través de la consola nos dirigimos al directorio raíz y lanzamos la orden Maven -> mvn eclipse:eclipse. Debiendo obtener una respuesta que muestre el correcto establecimiento de las dependencias entre los 3 módulos implicados
Repetir desde el paso 4 realizado para generar el proyecto org.gvsig.fortunecookies.lib.api para crear org.gvsig.fortunecookies.lib.spi (si se requiere) y org.gvsig.fortunecookies.lib.impl.
Si vamos a tener SPI, requeriremos de un provider que nos suministre los datos que necesitemos. Para ello, generaremos un paquete como org.gvsig.fortunecookies.lib creado en el punto 2 (que en este caso llamaremos org.gvsig.fortunecookies.prov), y añadiremos tantos providers como la aplicación utilice (en caso de tener varias fuentes de datos diferentes), que en nuestro caso se llamarán org.gvsig.fortunecookies.prov.webprovider y org.gvsig.fortunecookies.prov.fileprovider (la creación de éstos será igual que la de org.gvsig.fortunecookies.lib.api).
En este punto ya tenemos preparado nuestro proyecto para empezar a centrarnos en el desarrollo. En este segundo paso, tras configurar nuestro workspace con Eclipse, comenzaremos con la implementación del proyecto.
Vamos a implementar los métodos del API mínimos necesarios para que nuestra aplicación funcione:
Empezaremos con los proyectos FortuneCookieLocator y FortuneCookieLibrary que, como se ha comentado previamente, permiten acceder a los servicios que proporcionará el API.
FortuneCookieLibrary:
public class FortuneCookieLibrary extends AbstractLibrary{
protected void doInitialize() throws LibraryException {
}
protected void doPostInitialize() throws LibraryException {
}
}
FortuneCookieLocator:
public class FortuneCookieLocator extends BaseLocator{
private static final String LOCATOR_NAME = "FortuneCookieLocator";
public static final String MANAGER_NAME = "FortuneCookieLocator.manager";
public static final String MANAGER_DESCRIPTION = "FortuneCookie Manager";
private static final FortuneCookieLocator instance = new FortuneCookieLocator();
public static FortuneCookieLocator getInstance() {
return instance;
}
public String getLocatorName() {
return LOCATOR_NAME;
}
public static FortuneCookieManager getManager() throws LocatorException {
return (FortuneCookieManager) getInstance().get(MANAGER_NAME);
}
public static void registerManager(Class clazz) {
getInstance().register(MANAGER_NAME, MANAGER_DESCRIPTION, clazz);
}
}
FortuneCookieService
public interface FortuneCookieService extends Service{
public String getMessage() throws FortuneCookieMessageException;
}
- FortuneCookieManager
public interface FortuneCookieManager extends Manager {
public DynObject createServiceParameters(String serviceName) throws ServiceException;
}
- org.gvsig.tools.library.Library (creado en src/main/resources/META-INF/services)
org.gvsig.fortunecookies.FortuneCookieLibrary
Para la creación del SPI, requeriremos la interfaz del proveedor (FortuneCookieProvider) y del proveedor de servicios (FortuneCookieServiceProvider)
- FortuneCookieService:
public interface FortuneCookieProvider {
public String getMessage() throws Exception;
}
- FortuneCookieProviderServices:
public interface FortuneCookieProviderServices extends ProviderServices{
public DynObject getParameters();
}
El desarrollo del proyecto de Implementación contendrá la lógica interna que facilita los servicios especificados en el API y en el SPI. Para ello tendremos una clase DefaultFortuneCookieService y DefaultFortuneCookieManager que implementará los respectivos interfaces del API y una DefaultFortuneCookieProviderServices que hará lo propio con la interfaz del SPI. Además, deberemos añadir un Library para que el Locator registre nuestro manager (FortuneCookieDefaultImplLibrary)
- DefaultFortuneCookieService:
public class DefaultFortuneCookieService extends AbstractService implements FortuneCookie{
private String message;
private DefaultFortuneCookieManager manager;
public DefaultFortuneCookieService(DefaultFortuneCookieManager manager, DynObject parameters,
ProviderServices providerServices) throws ServiceException {
this.manager = manager;
this.message = null;
super.init(parameters, providerServices);
}
/*
* (non-Javadoc)
* @see org.gvsig.tools.service.Service#getProviderManager()
*
* This method must be implemented in all Services
*/
protected ProviderManager getProviderManager() {
return this.manager.getProviderManager();
}
/*
* (non-Javadoc)
* @see org.gvsig.tools.service.Service#getManager()
*
* This method must be implemented in all Services
*/
public Manager getManager() {
return this.manager;
}
public String getMessage() throws FortuneCookieMessageException {
if(message==null){
FortuneCookieProvider provider = (FortuneCookieProvider)this.getProvider();
try {
this.message = provider.getMessage();
} catch (Exception e) {
throw new FortuneCookieMessageException(e);
}
}
return this.message;
}
}
- DefaultFortuneCookieManager:
public class DefaultFortuneCookieManager extends AbstractManager implements FortuneCookieManager {
public DefaultFortuneCookieManager() {
super(new DefaultProviderManager());
}
/*
* (non-Javadoc)
* @see org.gvsig.tools.service.Manager#getService(org.gvsig.tools.dynobject.DynObject)
*
* This method must be implemented in all Managers
*/
public Service getService(DynObject parameters) throws ServiceException {
DefaultFortuneCookieProviderServices providerServices = new DefaultFortuneCookieProviderServices();
DefaultFortuneCookie cookie = new DefaultFortuneCookie(this, parameters , providerServices);
return cookie;
}
}
- DefaultFortuneCookieProviderServices:
public class DefaultFortuneCookieProviderServices extends AbstractProviderServices{
}
- FortuneCookieDefaultImplLibrary:
public class FortuneCookieDefaultImplLibrary extends AbstractLibrary{
protected void doInitialize() throws LibraryException {
FortuneCookieLocator.registerManager(DefaultFortuneCookieManager.class);
}
protected void doPostInitialize() throws LibraryException {
}
}
- org.gvsig.tools.library.Library (creado en src/main/resources/META-INF/services):
org.gvsig.fortunecookies.impl.FortuneCookieDefaultImplLibrary
Por último, se implementará el provider. Según el caso, podemos tener más de un proveedor de datos, que se implementará replicando este apartado tantas veces como proveedores haya (en nuestro caso se llamarán org.gvsig.fortunecookies.prov.webprovider y org.gvsig.fortunecookies.prov.fileprovider). Para generarlo requeriremos el proveedor, la factoría y la librería que lo registra, quedando de la siguiente forma:
- DefaultFortuneProviderLibrary registra la factoría del proveedor en el postinitialize:
public class FortuneCookieFileProviderLibrary extends AbstractLibrary{
protected void doInitialize() throws LibraryException {
}
protected void doPostInitialize() throws LibraryException {
ProviderManager mgr = (ProviderManager) FortuneCookieLocator.getManager();
mgr.addProviderFactory(new FortuneCookieProviderFactory());
}
}
- FortuneCookieProviderFactory
public class FortuneCookieProviderFactory implements ProviderFactory{
public static final String PROVIDER_NAME = "Provider";
public static final String PROVIDER_NAME_PARAMS = "FortuneCookieParams";
public static final String PROVIDER_NAME_PARAMS_DESCRIPTION = "";
private DynClass dynclass;
public Provider create(DynObject parameters, ProviderServices services) throws ServiceException {
return new FortuneCookieProvider(services);
}
public DynObject createParameters() {
DynObject dynobject = ToolsLocator.getDynObjectManager().createDynObject(dynclass);
...
//Here allocate the necessary parameters
...
return dynobject;
}
public String getName() {
return PROVIDER_NAME;
}
public void initialize() {
dynclass = ToolsLocator.getDynObjectManager().createDynClass(PROVIDER_NAME_PARAMS, PROVIDER_NAME_PARAMS_DESCRIPTION);
...
//Here allocate the necessary parameters
...
}
}
- Definiremos el proveedor (DefaultFortuneCookieProvider) que implementará los métodos establecidos en el SPI:
public class DefaultFortuneCookieProvider extends AbstractProvider implements FortuneCookieProvider{
public String getMessage() throws Exception {
...
//Here would define the method to get the message
...
}
}
En el caso que queramos disponer de interfaz de usuario en nuestra aplicación, también resulta interesante estructurar nuestro código, realizando una separación entre API e implementación.
De esta forma, se consigue definir una serie de clases que representan unos interfaces y ofrecen unas determinadas operaciones o funcionalidades, haciéndola independiente de su lógica. Esto permite poder llegar a realizar varias implementaciónes para satisfacer una necesidad siempre que respete el API.
A la hora de llevar a cabo esto podemos encontrarnos con casos similares a los que nos encontramos
a la hora de trabajar con la logica. Asi la forma mas simple nos la encontraremos
cuando tengamos un API y una implementacion de ese API que no precisa de implementaciones
alternativas o de proveedores de servicios para dar sus servicios.
Para poder llevarlo a cabo, emplearemos una estructura muy similar a la utilizada en el API e implementación
de la librería. A continuación, desglosaremos los elementos que componen cada uno de estos paquetes:
Al igual que en la librería, en este API se definen el conjunto de operaciones o servicios que ofrecen las interfaces de usuario (en este caso sólo está el JFortuneCookiePanel, aunque podrían haber más). Dentro de este paquete tendremos los siguientes componentes:
JFortuneCookiePanel. Desarrolla el API del panel principal que se mostrará con
la información de una instancia de FortuneCookieService. Entre los servicios que
podemos requerir será el de getFortuneCookie que nos devuelve la instancia
de FortuneCookieService que está representada en ese JPanel.
En general se tratara de una clase abstract que extiende a JPanel sin aportarle
nada mas que metodos abstractos. Siguiendo las mismas pautas que se han seguido
en la parte de logica deberia ser un interface que extendiese al interface de
swing del JPanel, pero como no disponemos de ese interface en swing lo simularemos
creando ka clase abstract.
FortuneCookieUIManager. Se encarga de instanciar los distintos interfaces de
usuario, y devolvérselos al cliente para que trabaje con
ellos. Además de hacer de factoría.
Dispondra de metodos como getJFortuneCookiePanel que nos devolveran una instancia
de JFortuneCookiePanel.
FortuneCookieSwingLocator. Al igual que en el Locator del Library
(FortuneCookieLocator), derivará de la clase AbstractLocator e implementará lo
necesario para poder recuperar una implementación del FortuneCookieSwingManager
que esté disponible.
FortuneCookieSwingLibrary. Extenderá la clase AbtractLibrary e implementará
los métodos "do*", normalmente dejándolos vacíos. En la parte del API (al igual
que ocurría con el FortuneCookieLibrary), no realiza ninguna operación.
Presenta la lógica que desarrolla la funcionalidad de las operaciones que nos proporciona el API.
- DefaultJFortuneCookiePanel.
Extendera de JFortuneCookiePanel y aportara la implementacion del panel que nos muestra
un FortuneCookieServices.
- DefaultFortuneCookieUIManager. Esta clase implementará el interface FortuneCookieUIManager,
encargándose de la creación de las instancias de nuestros interfaces JFortuneCookiePanel.
- DefaultFortuneCookieSwingImplLibrary. Al igual que en el proyecto del API aquí
tendríamos este library, que se encargaría de registrar la implementación de nuestro
manager para que pudiese ser recuperada por el Locator del API de esta parte de Swing.
La compilación de este proyecto nos generará una librería org.gvsig.fortunecookie.lib.api.jar
y org.gvsig.fortunecookie.lib.impl.jar (faltará el número de versión, que forma parte
de cada uno de los nombres)
Aunque aqui hemos usado JPanel como clase base para los componentes base que ofrece nuestra
libreria, puede darse el caso de que en lugar de JPanel sea mas conveniente usar otro
componente de swing como base de los nuestro, y asi Usar por ejemplo un JComponent o
uno mas concreto como el JEditPane. Cuando decidamos usar componentes concretos de
swing deberemos tener en cuenta que vamos a exponer el componente entero como parte
del API de nuestra libreria, de forma que el cambio de este en futuras implementaciones
causara una perdida de compativilidad importante. Solo deberiamos usar un comppnente de
swing concreto cuando este claro que este forma parte del API que vamos a exponer y no
como un efecto secundario de la implementacion que aportamos.
Documentación generada con maven: incluye JavaDoc, informes de test unitarios, validaciones de código, etc...